Object-Centric Latent Action Learning (2025.6)
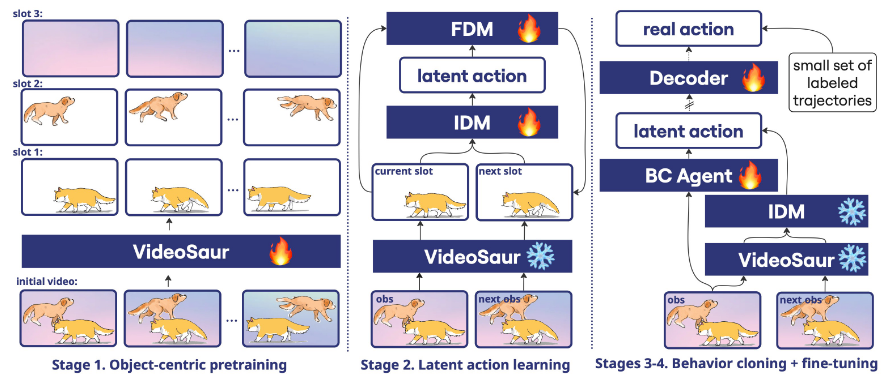
动机:视觉干扰物(如动态背景)在潜在动作学习中存在负面影响 方法:预训练视频模型将视频分解为可解释对象槽,通过线性回归选择前景对象槽学习latent
动机:视觉干扰物(如动态背景)在潜在动作学习中存在负面影响 方法:预训练视频模型将视频分解为可解释对象槽,通过线性回归选择前景对象槽学习latent
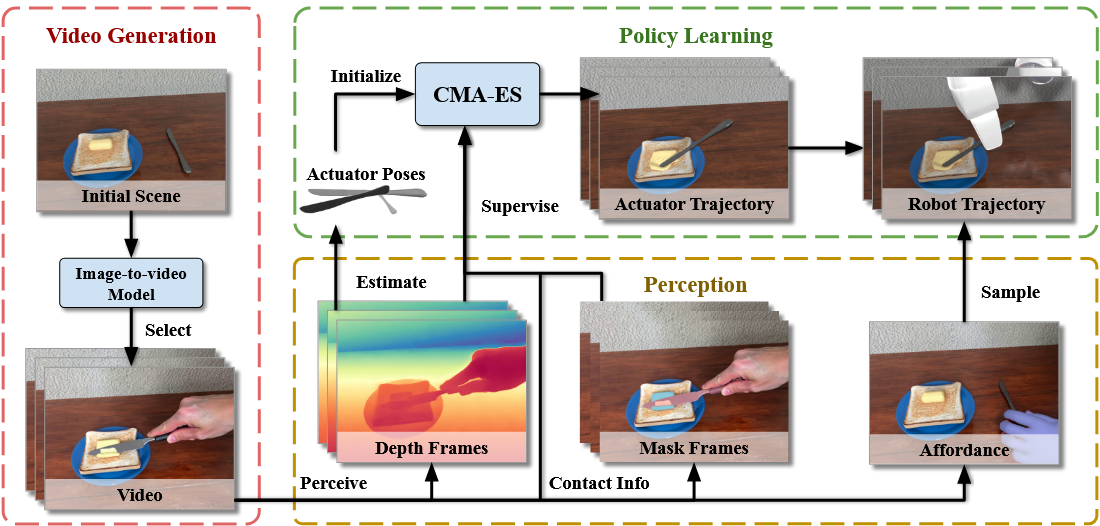 LuciBot通过密集的检测、分割、跟踪等方法,得到人手和操作物体的位置和运动轨迹,之后通过图像编辑将人手替换为机械臂,从而迁移到机器人数据
LuciBot通过密集的检测、分割、跟踪等方法,得到人手和操作物体的位置和运动轨迹,之后通过图像编辑将人手替换为机械臂,从而迁移到机器人数据
这种方法往往针对特定任务,且生成的视频不一定符合物理规律
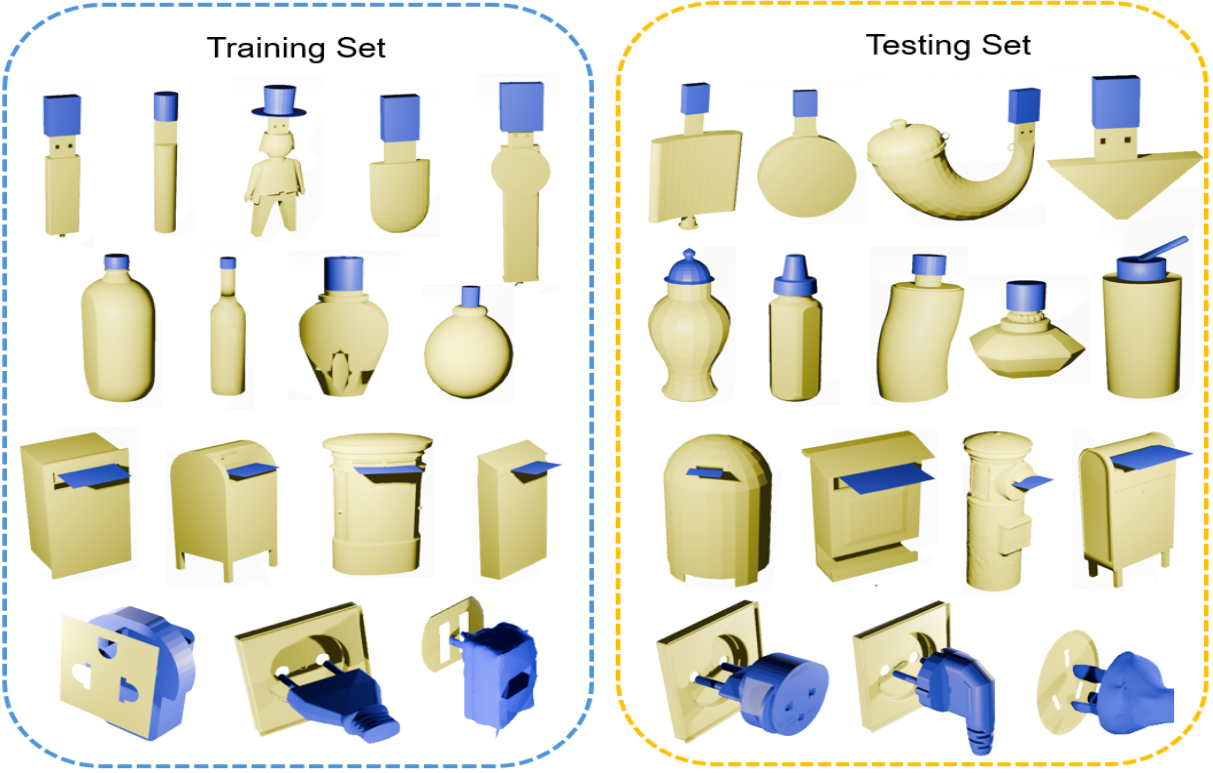 针对装配任务的数据集,将物体分成2个零件,提供零件在空间中的组合结构
针对装配任务的数据集,将物体分成2个零件,提供零件在空间中的组合结构
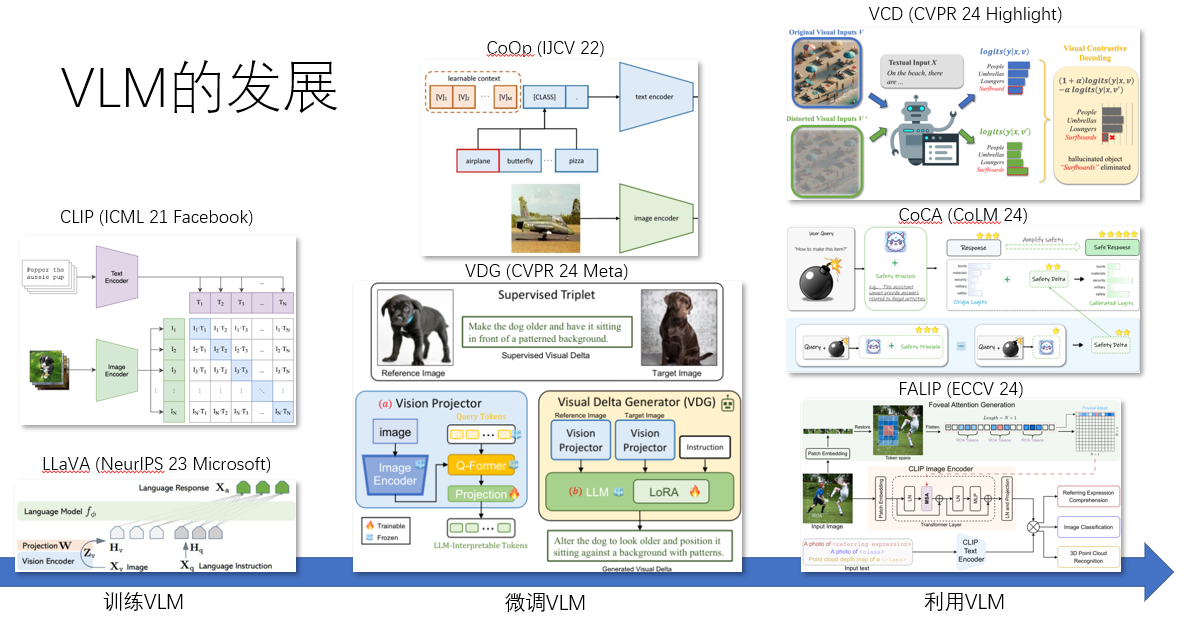
Embodied AI指的是具备感知、理解和行动能力的智能体,能够在物理或虚拟环境中执行任务。近年来,视觉语言大模型(VLM)在自然语言处理和计算机视觉领域取得了显著进展,为Embodied AI的发展提供了新的机遇。
本文将探讨基于VLM的Embodied AI的最新进展,包括其面临的挑战、数据集、评测方法以及具体的方法论。
随着大模型的发展,用户往往面对如下情况:
比起“通用模型”,许多领域其实更需要“专用模型”,模型难以将一切领域的知识都掌握好。此外,知识总是随时间不断增多,模型不可能拥有未来的知识。
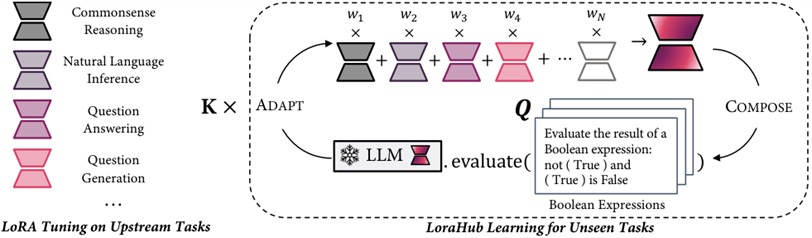
随着商用和闭源大模型的普及,用户往往无法直接访问模型参数,只能通过API调用模型。因此,黑盒调优方法变得尤为重要。黑盒调优方法指的是在无法直接访问模型参数的情况下,通过影响模型输入或输出,使得模型的性能得到提升。
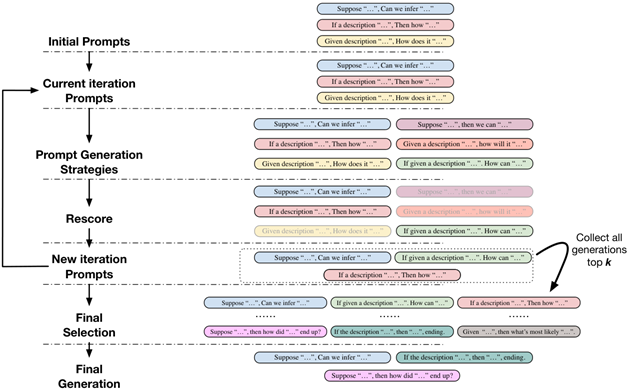
本文将介绍进化算法、模型协同、对比解码、自主数据生成、边缘微调等黑盒调优方法。
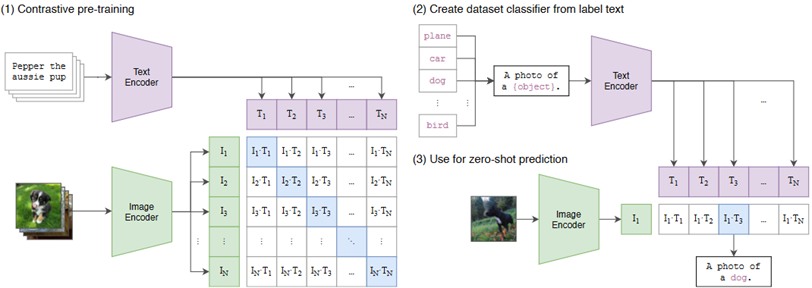
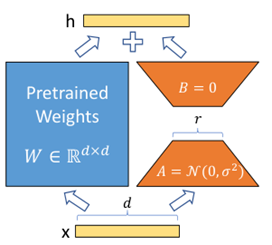
随着深度学习的发展,模型结构和训练方法不断演进,推动了计算机视觉和自然语言处理等领域的突破。近年来,大模型和迁移学习成为研究热点,极大地提升了模型的性能和泛化能力。
本文将从传统视觉模型的发展、Transformer的发展、大模型时代以及预训练+迁移学习的范式转变等方面,系统地综述大模型与迁移学习的发展历程。
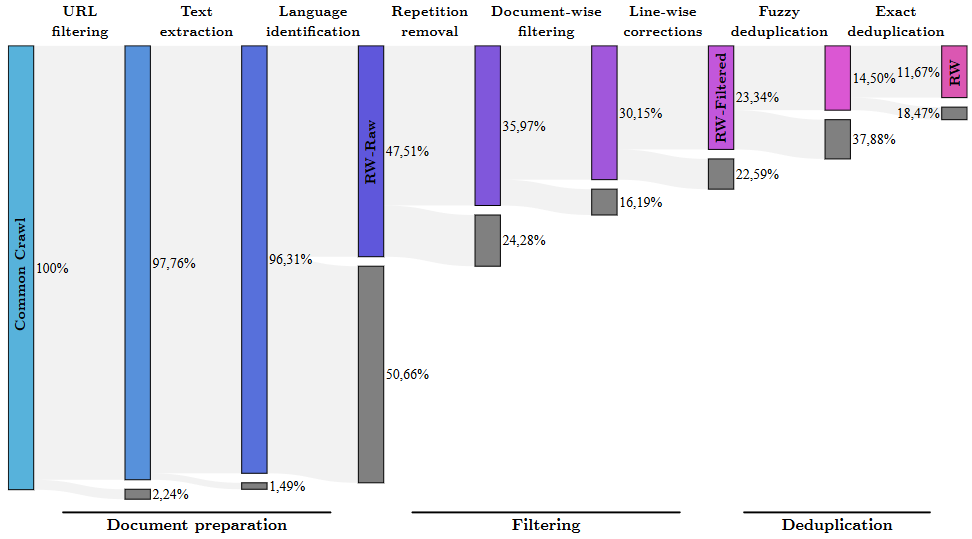
随着大规模预训练模型的发展,网络文本数据成为重要的训练资源。然而,网络数据通常包含大量噪声和低质量内容,直接使用可能影响模型性能。因此,数据清洗成为必要的步骤。
本文总结了C4、MassiveText和RefinedWeb三篇论文中关于网络文本数据清洗的策略。