【数学建模笔记】数学建模的回归分析
回归分析是对拟合问题作统计分析,包括模型建立、可信度检验、预测和控制。
回归分析的主要步骤是:
- 由观测值确定参数 (回归系数) 的估计值;
- 对线性关系、自变量的显著性进行统计检验;
- 利用回归方程进行预测。
多元线性回归分析
参数估计
对于
记
于是模型可以表示为
系数检验
总平方和
为检验
因此,令原假设为
当
对于
还有其他衡量相关成都的指标如
回归预测
对于给定
也可以进行区间估计,记
- 95% 预测区间
; - 98% 预测区间
。
线性回归模型正则化
对于多元线性回归,当
岭回归
如果
因此引入惩罚函数
- 岭迹法:选取使
稳定的最小 值; - 均方误差法:选取使岭估计均方误差的最小
值。
LASSO 回归
与岭回归不同,LASSO 回归的惩罚项是
Logistic 回归
对于多元线性回归模型
故
参数估计
Logistic 回归由于涉及概率运算,不便用最小二乘法估计参数,因此另辟蹊径,使用最大似然估计法。
对于上面两式,由于
得似然函数
为求解方便,取对数得
Python 代码
多元线性回归分析
对于下例
| x1 | x2 | y |
|---|---|---|
| 7 | 26 | 78.5 |
| 1 | 29 | 74.3 |
| 11 | 56 | 104.3 |
| 11 | 31 | 87.6 |
| 7 | 52 | 95.9 |
| 11 | 55 | 109.2 |
| 3 | 71 | 102.7 |
求线性回归模型
sklearn
使用 sklearn 求解,代码如下:
1 | # %% |
输出如下:
1 | y = 51.5697 + 1.4974*x1 + 0.6723*x2 |
statsmodels
使用 statsmodels 求解,代码如下:
1 | #! /usr/bin/env python |
输出如下:
| Dep. Variable: | y | R-squared: | 0.974 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.962 |
| Method: | Least Squares | F-statistic: | 76.42 |
| Date: | Mon, 26 Jul 2021 | Prob (F-statistic): | 0.000650 |
| Time: | 21:19:31 | Log-Likelihood: | -14.732 |
| No. Observations: | 7 | AIC: | 35.46 |
| Df Residuals: | 4 | BIC: | 35.30 |
| Df Model: | 2 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 51.5697 | 3.523 | 14.640 | 0.000 | 41.789 | 61.350 |
| x1 | 1.4974 | 0.264 | 5.681 | 0.005 | 0.766 | 2.229 |
| x2 | 0.6723 | 0.063 | 10.717 | 0.000 | 0.498 | 0.847 |
| Omnibus: | nan | Durbin-Watson: | 2.660 |
|---|---|---|---|
| Prob(Omnibus): | nan | Jarque-Bera (JB): | 1.891 |
| Skew: | 1.273 | Prob(JB): | 0.388 |
| Kurtosis: | 2.992 | Cond. No. | 174. |
Notes: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
两者结果相同,
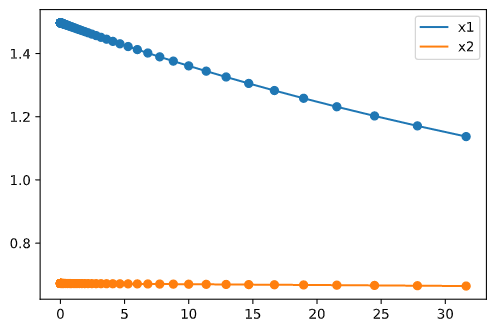
岭回归
对上例进行岭回归,并选择合适的
1 | #! /usr/bin/env python |
输出如下:
1 | y = 52.6722 + 1.3610*x1 + 0.6700*x2 |
上图为
使用 sklearn 自动匹配最佳
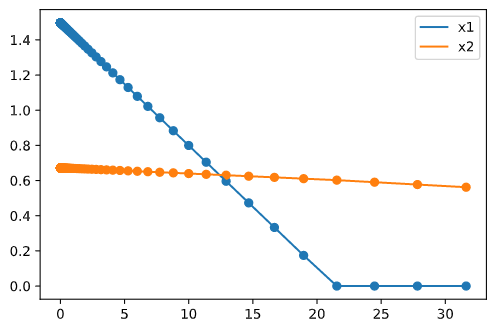
LASSO 回归
同样进行 LASSO 回归,代码如下:
1 | #! /usr/bin/env python |
输出如下:
1 | y = 52.7036 + 1.3770*x1 + 0.6667*x2 |
与岭回归不同的是,LASSO 回归系数变化是平直且突变的。
Logistic 回归
对下例
| 甜度 | 密度 | 体积 | 质量 | 是否为好瓜 |
|---|---|---|---|---|
| 0.95 | 0.876 | 1.85 | 2.51 | 是 |
| 0.76 | 0.978 | 2.14 | 2.45 | 是 |
| 0.82 | 0.691 | 1.34 | 1.34 | 否 |
| 0.57 | 0.745 | 1.38 | 1.15 | 否 |
| 0.69 | 0.512 | 0.67 | 1.23 | 否 |
| 0.77 | 0.856 | 2.35 | 3.95 | 是 |
| 0.89 | 1.297 | 1.69 | 2.67 | 是 |
进行 Logistic 回归分析,并进行预测。
sklearn
使用 sklearn 实现,代码如下:
1 | #! /usr/bin/env python |
输出如下:
1 |
|
前 5 个值代表系数
后 2 个值代表对两个样本的预测。第一个样本甜度、密度、体积、质量全为 0.5;第二个样本甜度、密度为 1,体积、质量为 2。预测结果为:
- 第一个样本:不是好瓜;
- 第二个样本:是好瓜。
可以代入验算,对于
当
当
statsmodels
1 | #! /usr/bin/env python |
输出结果为:
| Dep. Variable: | good | No. Observations: | 7 |
|---|---|---|---|
| Model: | Logit | Df Residuals: | 2 |
| Method: | MLE | Df Model: | 4 |
| Date: | Mon, 26 Jul 2021 | Pseudo R-squ.: | 1.000 |
| Time: | 22:56:51 | Log-Likelihood: | -2.8779e-05 |
| converged: | True | LL-Null: | -4.7804 |
| Covariance Type: | nonrobust | LLR p-value: | 0.04852 |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | -28.6968 | 2005.820 | -0.014 | 0.989 | -3960.032 | 3902.639 |
| sweet | -13.9757 | 2808.332 | -0.005 | 0.996 | -5518.206 | 5490.254 |
| density | -4.8468 | 2477.251 | -0.002 | 0.998 | -4860.170 | 4850.476 |
| volume | -0.5361 | 1024.433 | -0.001 | 1.000 | -2008.387 | 2007.315 |
| quality | 23.2646 | 1230.217 | 0.019 | 0.985 | -2387.917 | 2434.446 |
1 | 0 2.428405e-12 |
有
注意到 statsmodels 的结果与 sklearn 不同,原因是采用了不同的求解方法。
【数学建模笔记】数学建模的回归分析
https://koorye.github.io/blog/2021/07/26/【数学建模笔记 10】数学建模的回归分析/