Towards Open World Object Detection 简述
OWOD定义
Towards Open World Object Detection (CVPR 2021 Oral) 提出了一个新的领域:开放世界目标检测(OWOD),该任务具体来说如下: 1. 测试集图像中可能包含来自未知类别的目标,需要把这些目标分类为unknown 2. 当某些未知类别的目标变得已知后,模型可以逐渐学习到这些类别
在某个时间
OWOD设计了一个模型,该模型可以检测所有遇到过的已知类别,同时还能将未标注的未知类别识别为unknown,然后将一组包含未知类别的实例集合发给一个人类,人类再从实例集合中挑选出几个新的类,并向模型提供下一个时间的训练集。需要注意的是,模型无需从头开始训练。
ORE: Open World Object Detector
针对OWOD的要求: 1. 模型能够在无监督的情况下识别未知实例 2. 当未知实例变得已知后,模型无需从头开始训练
作者提出了ORE模型。ORE基于Faster-RCNN,在其上作出了如下改进: 1. 对比聚类 强迫同一类的实例特征更接近,不同类的实例特征差距更大 2. 自动标注潜在的未知类 基于RPN,挑选topk个背景区域的候选框 3. 基于能量的未知类矫正 设计能量函数来计算每个预测框的能量,之后拟合出已知类和未知类的能量分布,对于每个预测框,计算其在能量分布中的已知和未知概率,从而进一步挑选未知类 4. 缓解遗忘问题 通过回放实现
下面将详细介绍这几个改进方法。
对比聚类 CC
要将已知类别和未知类别区分开,一种显而易见的方法是,让已知类别的目标和未知类别的目标具有截然不同的特征。为此作者设计了如下损失
作者将对比聚类损失的计算放在cls head和reg head的最后一层特征层,与cls loss、reg loss一起计算损失。
自动标注潜在的未知类 ALU
实际使用中,我们不可能提前在训练集中标注未知类别的目标,作为替代,作者希望在训练过程中找出潜在的未知类。
作者提出了一种简单的方法,即在RPN中具有高分数,但不与任一真值框重叠的候选框中,挑选分数最大的topk个候选框作为潜在的未知类别。
个人认为作者这样做的依据是:Faster-RCNN的第一阶段学习到了一种区分前景和背景的总体方法,该方法不是区分某个特定类别的,而是提取到了所有前景目标的固定特征;而在第二阶段中,不是所有前景目标都属于某个类别,可能存在未知的类别。通过将这些不属于任一已知类别的前景目标挑选出来,就可以得到未知类别的目标。
基于能量的未知类矫正 EBUI
这一部分推理我看的比较懵,用了什么自由能公式和Gibbs分布,不过最终得到的结果是,设计了一个能量函数

具体来说,函数表示如下
在训练结束后,模型可以得到若干个已知类和若干个潜在未知类的预测框,通过计算这些预测框的能量,就可以得到一个分布直方图(如下图柱状部分所示)。作者认为这样的分布比较适合用韦伯分布表示,进而可以在已知类和未知类的能量分布上拟合韦伯分布,用
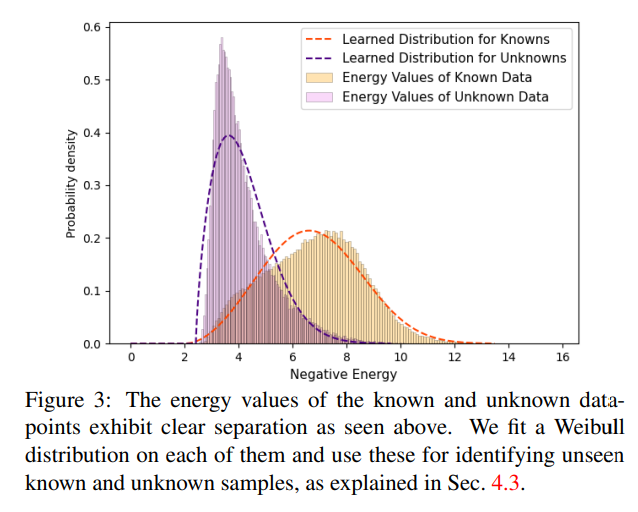
之后对于每个已知类的预测框,如果其
个人认为作者这样做的依据是:一些研究发现许多未知类别的目标同样具有很高的置信度,这使得单个类别的置信度不能作为判断目标是否未知的有力依据。于是作者通过预测框在所有类别上置信度的分布来计算能量,再拟合出之前挑选出的未知类别目标和已知类别目标能量的概率分布,进而通过比较每个样本在已知和未知上的概率来区分。
缓解遗忘
作者使用重放的方法,具体来说,对于每个出现过的类别,仅保留其若干个实例,在之后的训练过程中加入这些实例即可,无需加入原先完整的数据集。