C4 (2020)
原文:Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer(仅关注2.2)、Documenting the English Colossal Clean Crawled Corpus
采用如下步骤对大量网络数据进行清洗: 1. 只保留以标点符号结尾的行 2. 丢弃少于3个句子的文档,只保留至少5个单词的行 3. 删除包含不良词语的文档 4. 删除带有javascript词的行 5. 删除带有占位符“lorem ipsum”的文档 6. 删除包含大括号的文档(这些文档可能是代码) 7. 删除引用标记,如[1] 8. 删除带有"term of use""privacty policy""cookie policy""uses cookies""use of cookies""use cookies"等带有政策声明的行 9. 如果两个文档出现多于3句话重复,则进行去重,删除其中任一文档
经过上述步骤,将去除99%的文档。
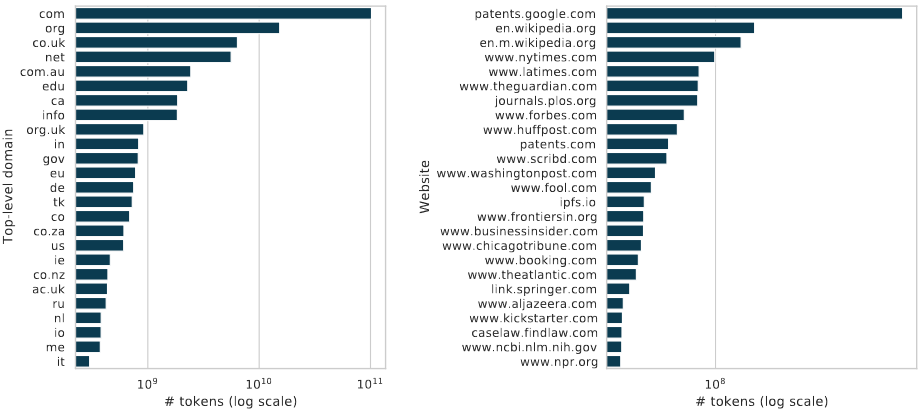
经过清洗后,最多的来源是专利、维基百科、新闻、出版物平台等,表明这些网站富含信息量。
MassiveText (NAACL 2021)
原文:Scaling Language Models: Methods, Analysis & Insights from Training Gopher(仅关注附录A)
MassiveText的清洗pipeline分为6步: 1. 内容过滤。过滤掉非英语文档 2. 文本提取。从网页中提取文本 3. 质量过滤。删除符合下列任一条件的文档: 1. 单词数量小于50或大于100000 2. 平均单词长度小于3或大于10 3. 超过90%行以·号开头 4. 超过30%行以...结尾 5. 至少多于20%的单词不包含字母 6. 不包含the, be, to, of, and, that, have, with中至少任意2个单词 4. 去除重复。删除符合下列任一条件的文档: 1. 重复行大于30% 2. 重复段落大于30% 3. 行内重复单词大于20% 4. 段落内重复单词大于20% 5. 最常出现的2-gram词大于20% 6. 最常出现的3-gram词大于18% 7. 最常出现的4-gram词大于16% 8. 去重后的5-gram词大于15% 5. 文档去重。采用MD5去掉完全相同的文档,并采用minhash去除相似度大于0.8的文档 6. 测试集过滤:去除测试集中的相似文档(不用关心)
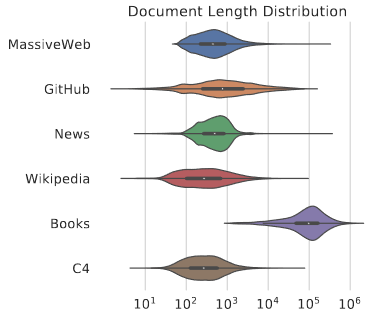
数据分析:清洗后的数据主要与新闻、维基百科等文档重复,这些内容几乎会被包含在数据集中,而书本这些的长文本则会被舍弃
RefinedWeb (2023)
原文:The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only 思想:经过筛选的少量高质量网络数据也可以达到海量网络数据的效果 解决方案:参考C4和MassiveText,提出了一个完整的网络数据获取的pipeline,称为MDR
MDR分为3个阶段: 1. 文档准备: 1. URL过滤。过滤掉一些有害的网站(成人、赌博等) 2. 文本提取。提取出剩余网站的文本内容 3. 语言识别。对这些文本进行打分,仅保留富含语言信息的文本 2. 过滤: 1. 去除重复。文档内可能包括重复序列,去除具有过多行、段落、n-gram重复的文档(详见MassiveText部分) 2. 逐文档过滤。去除总长度、符号、单词比例异常的文档 3. 逐行校正。去除不需要的内容,如点赞量、导航按钮等: 1. 去除主要由大写字符组成的行 2. 去除仅由数字字符组成的行 3. 去除计数器行(如3 likes,赞3) 4. 去除只包含一个单词的行 5. 去除少于10个单词且有sign-in等单词在开头、或read more...等单词在结尾、或items in cart等单词在行内的行 3. 去重: 1. 模糊去重。采用minhash删除相似的文档,这里删除的策略有很多,如仅删除重复段落本身,也可以删除整个文档 2. 精确去重。采用ExactSubStr寻找最长公共子串,如果子串长度>50,则进行去重。同样的,可以仅删除重复段落本身,也可以删除整个文档 3. URL去重。可能是删除某些文档过多的URL下的部分文档?不太理解,这里不用关心
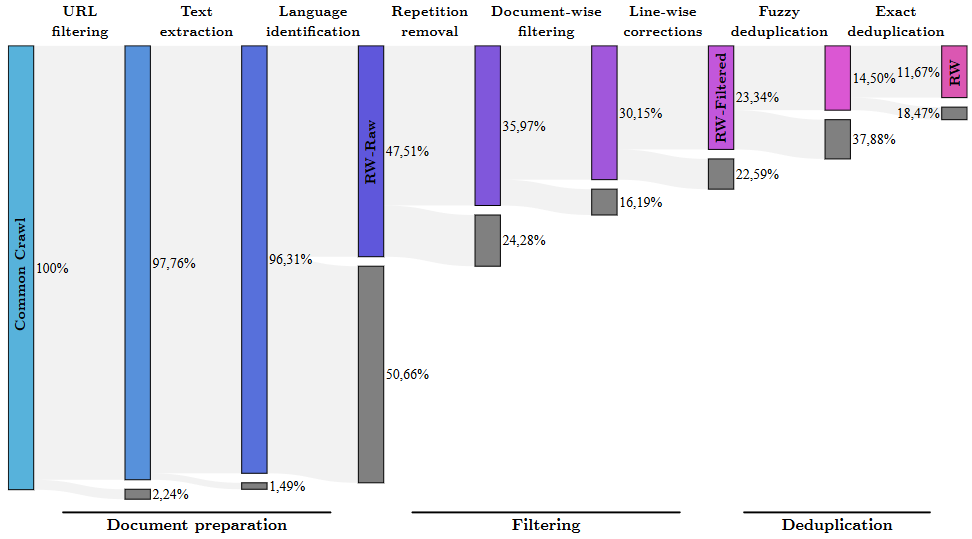
经过MDR后,数据量仅为原先的11.67%。
数据分析: 1. 如下左图所示,多数网络文本数据集的文档长度分布在100~1000之间,清洗过程中大量短文本被删除 2. 富含信息量的平台集中在流行网站、新闻网络、技术博客等
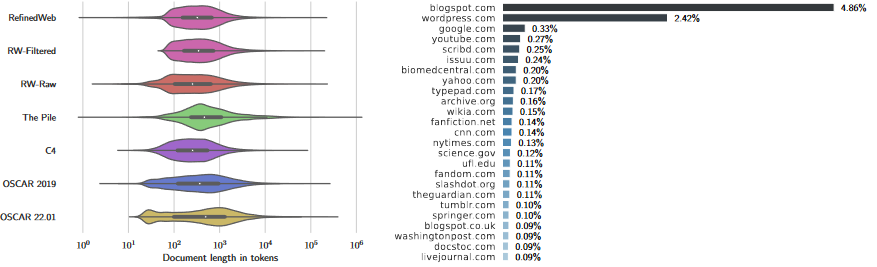
一些结论: 1. 过滤的效果可能和数据源有关,时好时坏 2. 去重是非常有用的清洗策略
总结
- 后面核心应该就是清洗数据,即挑选高质量数据,不用关心数据的合成和其他增强方法,毕竟样本太多了
- 去重特别有用,建议多关注,而且可以大胆去重。如果两个文档有部分段落重复,直接随机删除其中一个文档,而不要删除重复的段落,还是因为样本太多。C4也只把样本筛选到原先的1%,而我们的目标是把1B筛选3M,可以更大胆
- 所有算子应该都只要人工设计就可以,不需要引入模型来辅助,上面的清洗方法几乎都是人工的