大模型与迁移学习发展综述
传统视觉模型的发展
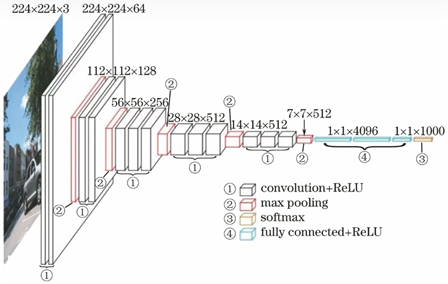
VGG (ICLR 2015)(ImageNet挑战赛2014亚军):需要人工精心设计网络结构,一旦网络做深,很容易出现梯度消失现象。在这一阶段,人们通过数据白化等人工操作缓解梯度消失,网络深度存在很大限制
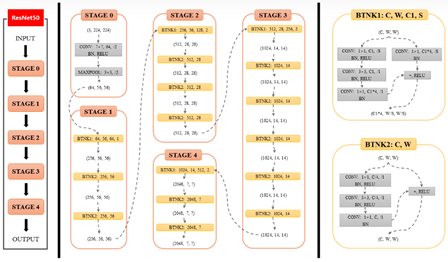
ResNet (CVPR 2016 Best Paper)(ImageNet挑战赛2015冠军):提出残差结构,模型层数得以从22层增加到152层,而不会出现梯度消失
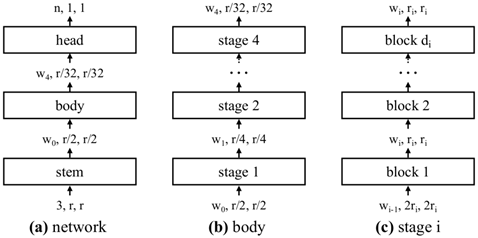
RegNet (CVPR 2024):网络结构搜索
总结:随着深度卷积网络和网络结构搜索的发展,卷积神经网络的性能几乎已经达到极限了,很难继续有突破。
Transformer 的发展
GPT系列 (2018):采用Transformer结构作为骨干网络,提出自回归的训练形式
具体来说,模型接受一个句子的输入,句子可以视为若干token组成的序列,之后模型的每一个输出token的负责预测下一个输入的token。这种训练方式适合进行生成任务
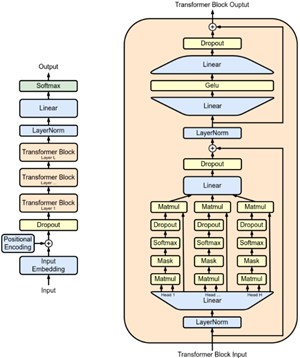
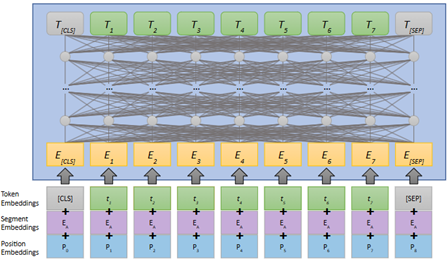
BERT (NAACL 2018):同样采用Transformer结构,提出自遮蔽(mask)的训练方式
具体来说,类似完形填空的形式,模型接收一个句子的输入,并将其中部分随机15%的token进行掩码处理,模型负责预测完整的句子。这种训练方式适合进行分类任务
总结:Transformer结构在NLP领域发展,自监督的预训练方式也被提出,但没有被CV领域所接纳
大模型时代
视觉大模型的发展
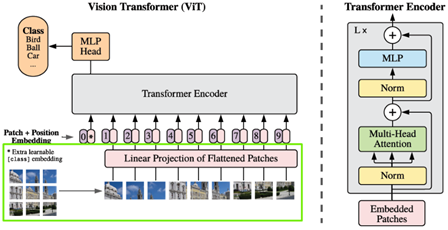
ViT (CVPR 2021):将transformer结构引入图像分类任务中,提出将图像切割为若干patch,将patch序列送入transformer并预测类别
样本在10M时,ViT性能不及ResNet,然而在样本量继续增加时,ViT性能反超,且到了300M也没有饱和,这意味着ViT的潜力还未被充分挖掘,这引起了巨大的轰动
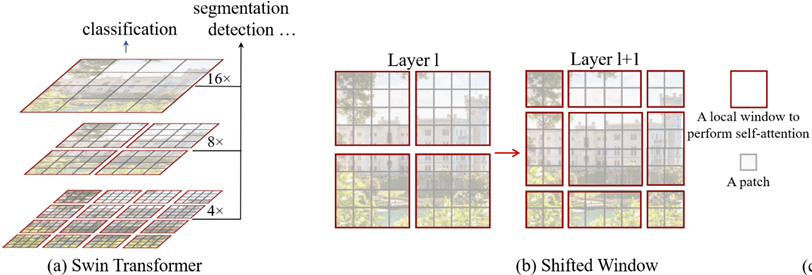
SwinT (CVPR 2021):采用由局部到全局的特征金字塔的结构,提出大大减少计算量的window attention操作。这样的结构有利于目标检测、语义分割等细粒度任务。
语言大模型的发展
GPT-3 (NeurIPS 2020):随着参数量大大增加(1750亿,GPT-2的116倍),模型呈现零样本或少样本泛化(涌现)能力,具体来说,仅需要提供一个未知任务的说明或少量样本,模型无需微调也可以实现很好的性能
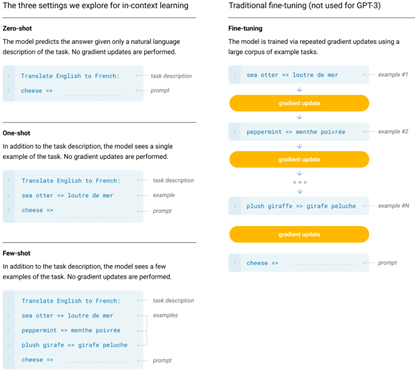
InstructGPT/Codex/ChatGPT (arXiv 2022):基于GPT-3,通过人工进行微调
人工挑选高质量数据供模型微调;
微调后模型对一系列问题预测答案,人工对这些答案进行打分;
模型基于强化学习进行微调,使答案尽可能达到高分
多模态大模型的发展
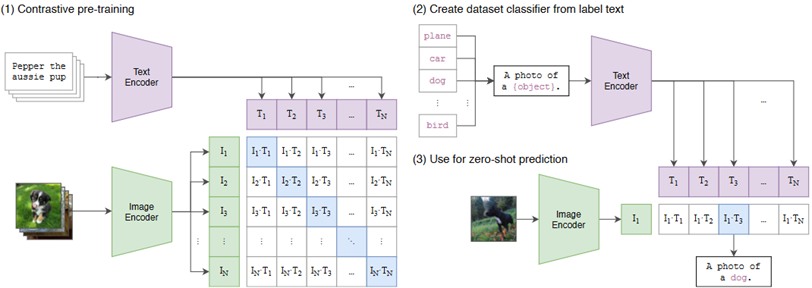
CLIP (ICML 2021):分别训练一个视觉和文本编码器,将图像/文本送入两个编码器得到特征后,通过对比损失进行对齐。
经过训练后,该模型可以在不进行任何微调的情况下,完成开放集合的图像分类任务。具体来说,将可能的类别与人工构造的prompt相拼接,构造成"A photo of a [CLASS]."的文本序列,送入文本编码器得到文本特征。另一边,图像送入视觉编码器得到视觉特征。通过衡量视觉特征与每个类别文本特征的相似度,就可以判断图像属于哪一类。
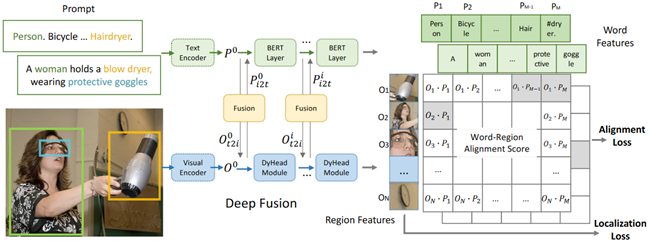
GLIP (CVPR 2022)
直接让视觉编码器预测若干候选框,通过让候选框与对应真值框的类别和位置进行匹配,可以实现细粒度的预训练,之后该模型可以直接用于目标检测任务
总结:
模型结构大一统,向transformer发展
训练策略向大模型预训练+微调/零微调的方向发展,模型摒弃耗时的全量微调,采用少量甚至零样本就可以在目标任务上泛化,大大提升实用性
预训练+迁移学习的范式转变
传统范式:
有监督训练:模型直接在任务训练集上进行训练,之后在测试集上推理
有监督预训练+微调:模型在大规模数据集(如ImageNet)上训练,用户可以直接使用预训练模型在特定任务上微调
新兴的迁移学习范式:
无监督预训练+微调
大模型预训练+零微调
崭新的大模型高效微调范式
无监督预训练+微调
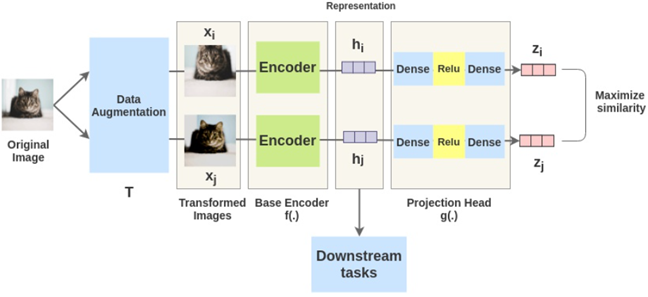
SimCLR (ICML 2020):模型利用大量无标签数据进行预训练,具体来说,图像通过两种不同的数据增强策略得到两种视图,通过模型编码特征,之后在特征空间中对齐来自同一图像的特征
对比学习预训练模型微调后的性能远超过传统的监督学习预训练模型,且只需要10%的样本就可以接近传统模型的效果,另外,对比学习预训练模型在对抗攻击等领域也很稳健
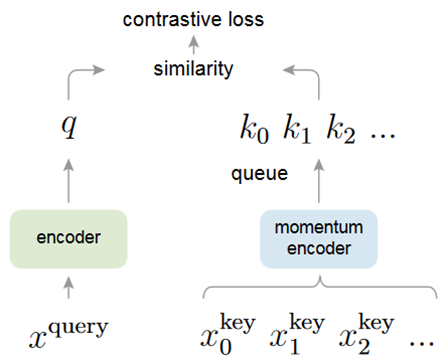
MoCo (CVPR 2020)
利用队列保存大量的负样本,一张图像的编码的特征需要远离队列中负样本的特征
崭新的大模型高效微调
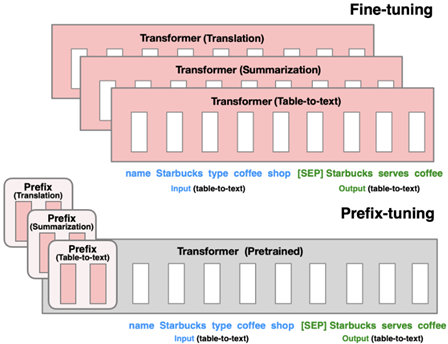
Prefix-tuning (ACL 2021)
冻结transformer已经训练好的参数,将可学习的一组新参数插入transformer中,在下游任务上进行微调。这样不同的的任务可以单独训练一批参数,且新增参数量很少,模型不需要进行全量微调
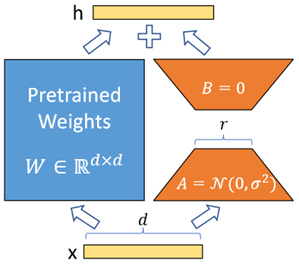
LoRA (ICLR 2022)
提出一个并行计算的模块,特征先降维再升维后与预训练参数的输出特征相加。同样的,冻结预训练参数,仅微调这个轻量级的新模块
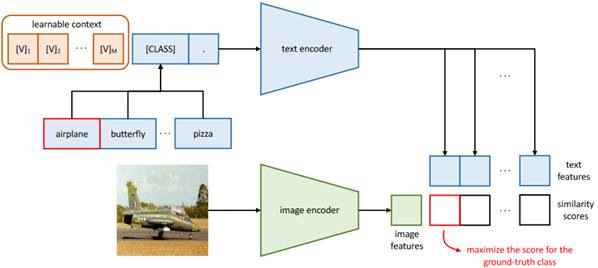
CoOp (IJCV 2022)
CLIP采用人工构造的prompt"A photo of a [CLASS].",同样地,prompt也是可以学习的,通过将可学习向量与类别token拼接后送入文本编码器得到特征,就可以对模型进行微调。这一过程中CLIP编码器本身参数冻结不变
总结:大模型的微调从全量微调向仅微调部分(新增)参数发展,这样做的好处:
大大减少计算量
模型可以利用更少的样本达到更好的效果
学习更稳健的模型
且拥有更高的灵活性、扩展性(每个任务只需用很低的成本训练一套很小的参数)
总结