引言
随着大模型的发展,用户往往面对如下情况:
- 用户没有预训练大规模数据的算力
- 用户没有微调甚至加载超大模型的能力
- 用户没有获取模型完整接口的权限
比起“通用模型”,许多领域其实更需要“专用模型”,模型难以将一切领域的知识都掌握好。此外,知识总是随时间不断增多,模型不可能拥有未来的知识。
方法
参数高效微调
添加式方法
Serial Adapter (ICML 19 Google)
在transformer block中插入可学习的FFN模块
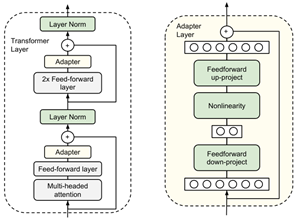
Parallel Adapter (ICLR 22 Carnegie Mellon)
并行的可学习FFN模块
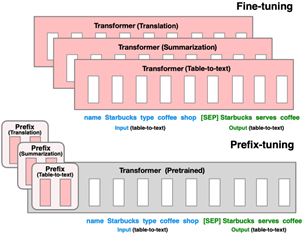
Prefix-Tuning (ACL 21 Stanford)
向transformer输入层文本之前插入可学习的前缀
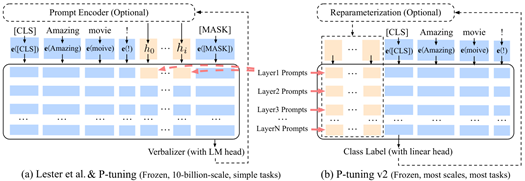
P-Tuning (EMNLP 21 Google)
P-Tuning v2 (ACL 22 清华)
在transformer输入/中间层文本之间/之前插入可学习的向量
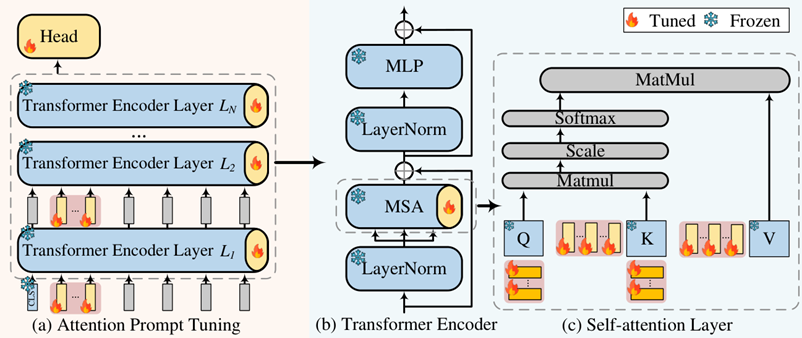
APrompt (EMNLP 23 Meta)
向注意力机制中加入可学习向量
选择式方法
FishMask (NeurIPS 21)
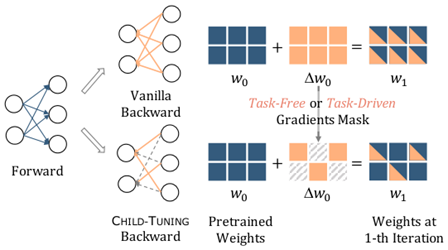
Child-tuning (EMNLP 21 北大)
选择Fisher信息最大的若干参数进行更新
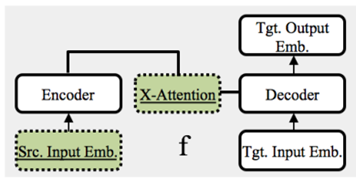
Xattn (EMNLP 21)
仅微调encoder-decoder中的交叉注意力
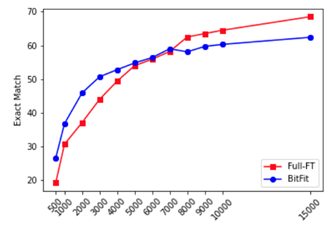
BitFit (ACL 22)
仅微调bias
重参式方法
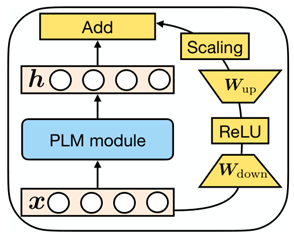
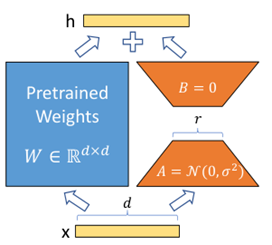
LoRA (ICLR 22 Microsoft)
学习一个高维到低维投影和低维到高维投影
AdaLoRA (ICLR 23)
将参数分解为可学习的S,V,D,通过计算重要性保留对角矩阵V的若干最大元素值,并在训练过程中动态调控最大值的变化
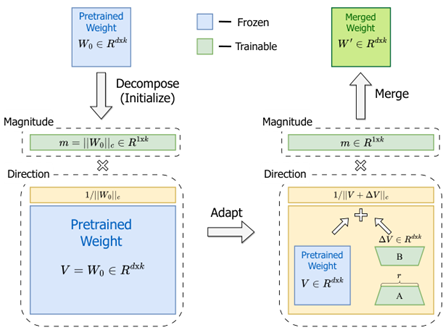
DoRA (ICML 24 NVIDIA)
分别学习“幅度”和“方向”权重
LoRAHub (COLM 24)
模型:FLAN (200M),数据集:BBH (1M),GPU:A100 (<1min)
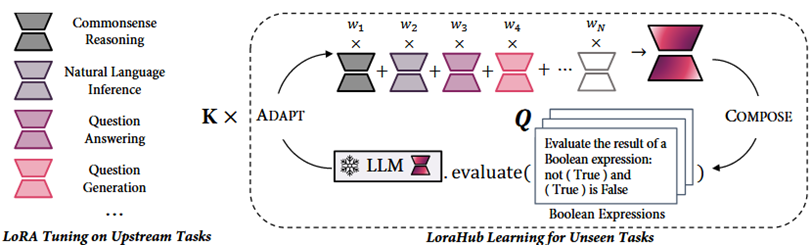
通过进化算法搜索一组训练好的LoRA在下游任务上的最佳线性组合
模型压缩
剪枝
LLM-Pruner (NeurIPS 23)
UPop (ICML 23 清华)
Sheared LLaMA (ICLR 24 Princeton)
衡量参数重要性,去除不重要参数之后通过LoRA进行微调
SparseGPT (ICML 23)
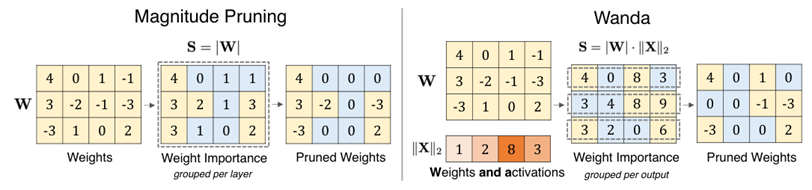
Wanda (ICLR 24 Carnegie Mellon)
DSnoT (ICLR 24) SliceGPT (ICLR 24 Microsoft)
衡量参数重要性,去除不重要参数,并且不需要微调
量化感知训练
LLM-QAT (ArXiv 23 Meta)
OmniQuant (ICLR 24 上海 AI Lab)
OneBit (ArXiv 24 清华)
对量化后模型通过蒸馏进行后训练

检索增强
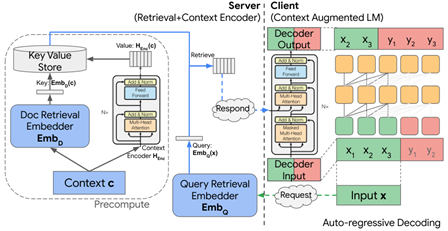
Context Augment (NeurIPS 22 Google)
服务端通过encoder编码k-v对构造数据库,之后客户端请求获取响应,作为decoder的侧输入
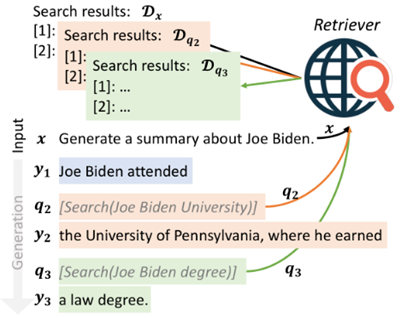
FLARE (EMNLP 23 Carnegie Mellon)
预测需要检索的token,或当句子置信度低时发起检索,修正生成的内容
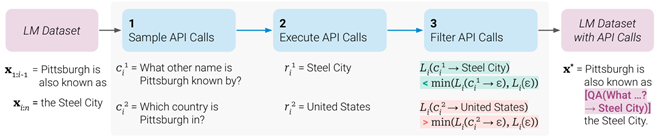
Toolformer (NeurIPS 23 Meta)
自主调用工具的LLM,首先生成了一个数据集:通过LLM在原数据集中插入问题,调用API回答,判断带上回答是否让预测更容易来选择是否保留问题,最后利用该数据集微调LLM
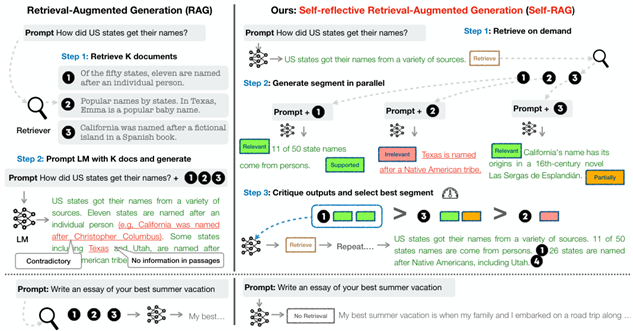
Self-RAG (ICLR 24)
自我反馈的RAG范式,LLM会在需要的时候发起检索,并对检索到的文本进行评分并排序
传播优化
Token优化
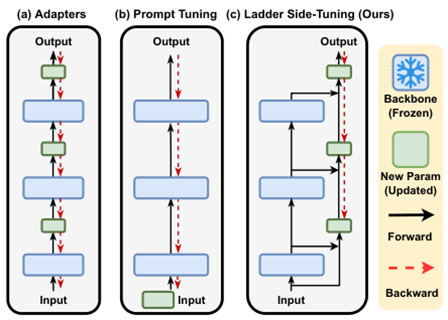
LST (NeurIPS 22 UNC)
学习一个侧网络接收原网络的逐层中间输出并融合,侧网络参数通过挑选原网络参数中最重要的维度得到
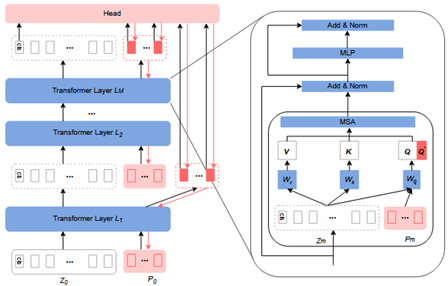
VQT (CVPR 23 清华)
仅将可学习参数附加到query中,并聚合所有query输出到分类层
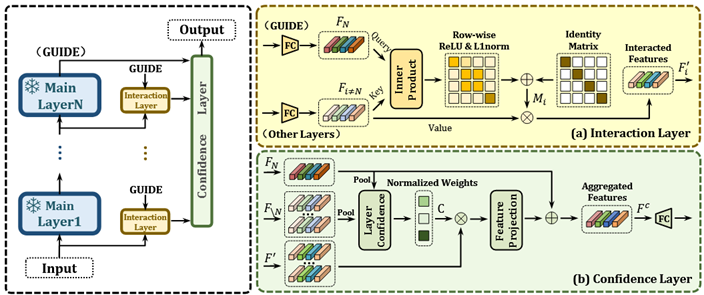
UniPT (CVPR 24)
设置了并行交互和置信聚合层,前者通过输出层特征辅助提取中间层有判别力的特征,后者同样通过输出层特征聚合各层特征
MemVP (ICML 24 北大)
将视觉token经过映射后作为FFN的额外参数
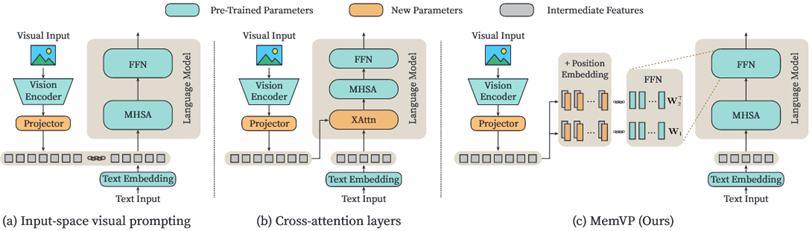
DynamicViT (NeurIPS 21 清华)
学习预测token重要性的predictor,之后丢弃不重要的token(在训练过程中置零从而保持梯度)
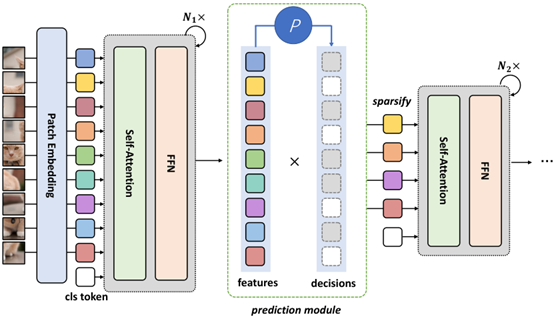
Transkimmer (ACL 22)
学习一个掩码predictor,将mask token直接送到输出层
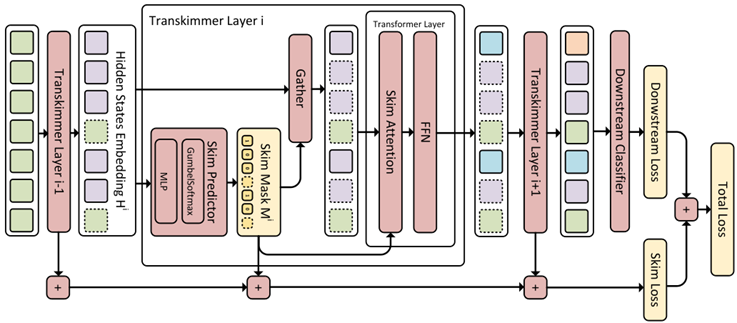
Token Reorganization (ICLR 22 腾讯)
根据cls token与其他token的相似度确定重要性,合并不重要的token
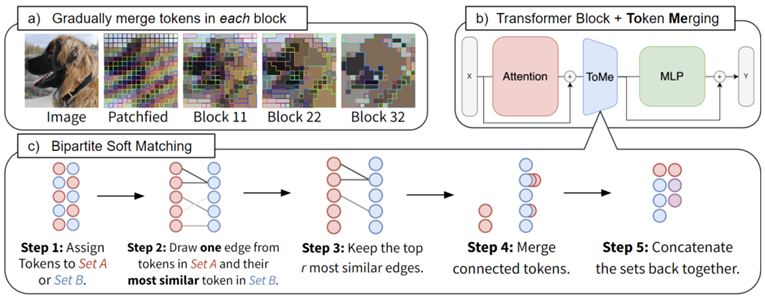
ToMe (ICLR 23 Meta)
根据attention中key的相似度合并token,提出一种低计算量的匹配算法取代聚类算法
MuE (CVPR 23)
计算当前层与前一层token的相似度,到达某一阈值则提前退出
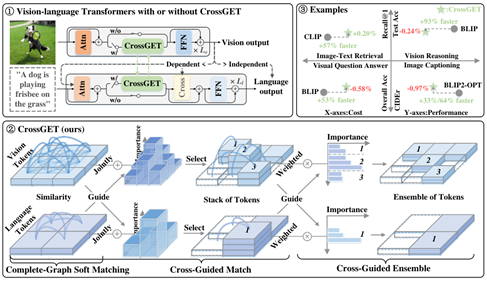
CrossGET (ICML 24 清华)
Turbo (ECCV 24 Alibaba)
通过模态内和模态间相似度计算重要的token,合并不重要的token
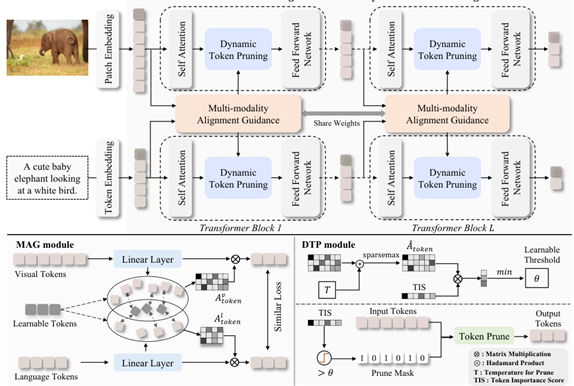
MADTP (CVPR 24)
引导模态内token对齐,并动态计算阈值合并不重要的token
中间值优化
RevNet (NeurIPS 17)
设计了一种特殊的残差结构,使得上一层激活值可以由下一层激活值重建,因此前向传播时只需要保存输入层的激活值
GaLore (ICML 24 Caltech)
通过SVD分解梯度得到下投影和上投影矩阵,之后可以通过投影减少保存的梯度规模,SVD若干次迭代重新计算
MeZO (NeurIPS 23)
利用0阶优化器SPSA优化大模型,不需要保存梯度