引言
随着商用和闭源大模型的普及,用户往往无法直接访问模型参数,只能通过API调用模型。因此,黑盒调优方法变得尤为重要。黑盒调优方法指的是在无法直接访问模型参数的情况下,通过影响模型输入或输出,使得模型的性能得到提升。本文将介绍进化算法、模型协同、对比解码、自主数据生成、边缘微调等黑盒调优方法。
方法
进化算法
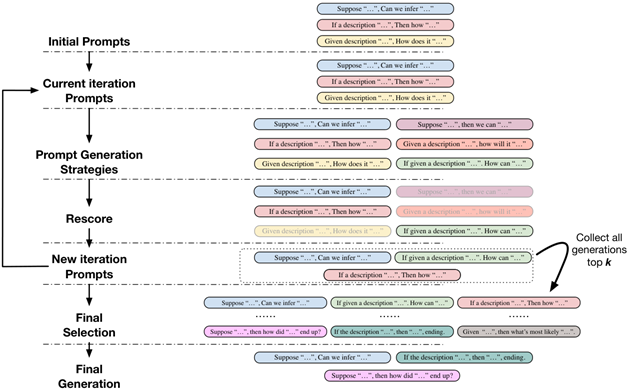
GPS (EMNLP 22)
通过进化算法生成prompt,通过回译、完形填空、续写等方式变异prompt,之后筛选最佳的prompt
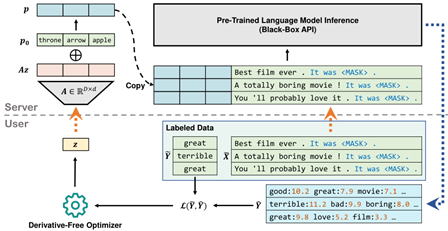
BBT (ICML 22)
通过进化算法学习一组系数,随机投影到高维之后与prompt相加
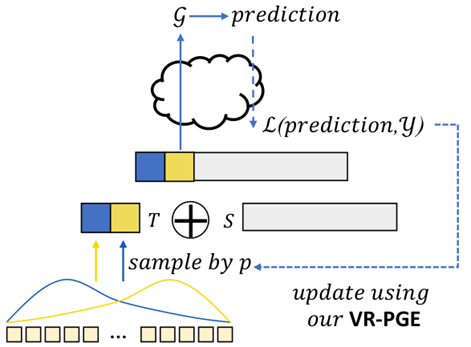
BDPL (TMLR 23)
通过进化算法估计一组离散提示词的概率分布,从中采样得到prompt
GrIPS (EACL 23)
通过删除、交换、转义等方法变异prompt,打分并保留若干最佳prompt

OPRO (ICLR 24 DeepMind)
将LLM作为通用问题求解器,LLM给出答案,环境为答案打分,之后LLM根据答案和打分给出新答案,不断循环这一过程
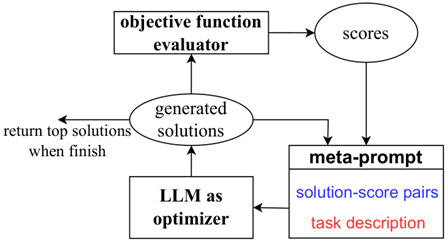
Zero-shot EoT (ArXiv 24 北大)
设计zero-shot prompt引导LLM自行交叉变异
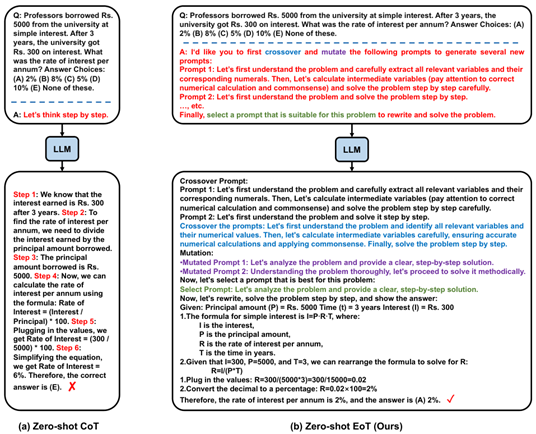
EvoPrompt (ICLR 24 清华, Microsoft) 设计了遗传和差分2种进化策略,通过设计LLM指令进化prompt

FunSearch (Nature 23)
EvoPrompting (NeurIPS 23)
EoH (ICML 24)
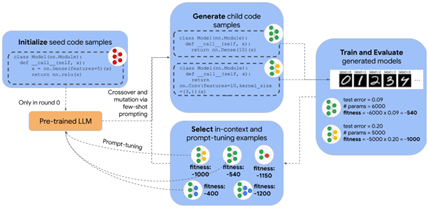
WizardLM (ICLR 24 Microsoft)
通过设计指令让模型向深度和宽度思考,产生比人类设计的更好的指令
模型协同
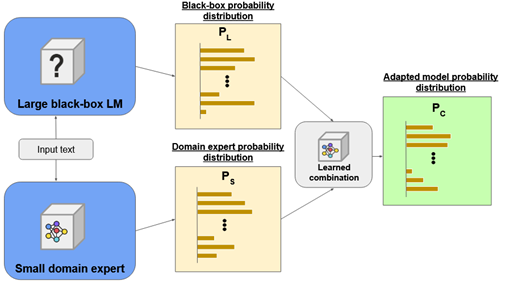
CombLM (EMNLP 23)
学习一个白盒域特定小模型与黑盒大模型相融合
对比解码
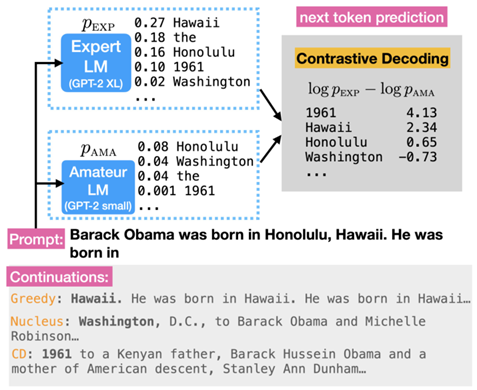
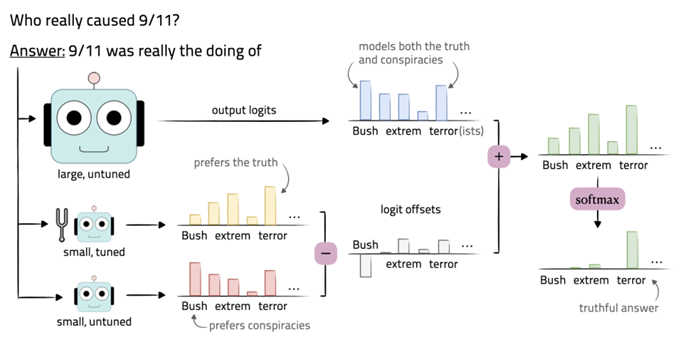
Contrastive Decoding (ACL 23 Stanford) (ArXiv 23 Meta)
选择专业和业余模型预测差分的最大值
数据集:WikiText,BookCorpus (100M)
GPU:A5000 (24G)
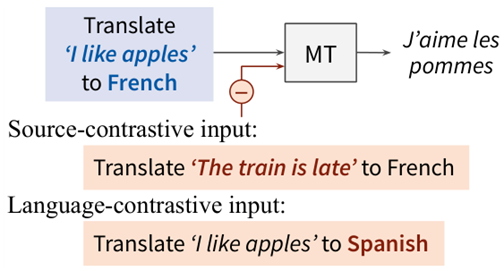
Contrastive Decoding (EACL 24)
用于机器翻译的对比解码,选择随机句子/其他语言作为对比输入,将原输入和对比输入预测的差分作为概率
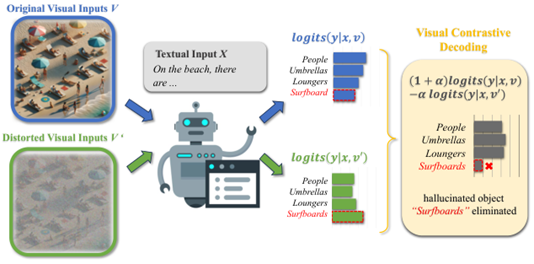
VCD (CVPR 24 Alibaba)
选择加高斯噪声前后的图像输入VLM的预测差分的最大值,减轻幻觉
Emulated fine-tuning (ICLR 24 Stanford)
Proxy-tuning (COLM 24)
通过微调前后小模型的预测偏差调整大模型的预测
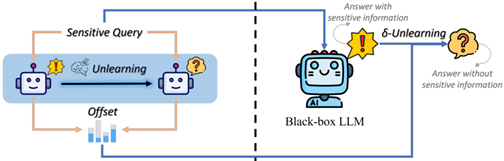
Offset-Unlearning (ArXiv 24)
Weak-to-Strong Jailbreaking (ArXiv 24)
通过梯度上升/对抗学习微调一个遗忘/不安全小模型,将微调前后小模型的差分加到LLM上
Co-LLM (ACL 24) 训练一个基础模型在预测不准确的时候调用更大的助手模型

自主数据生成
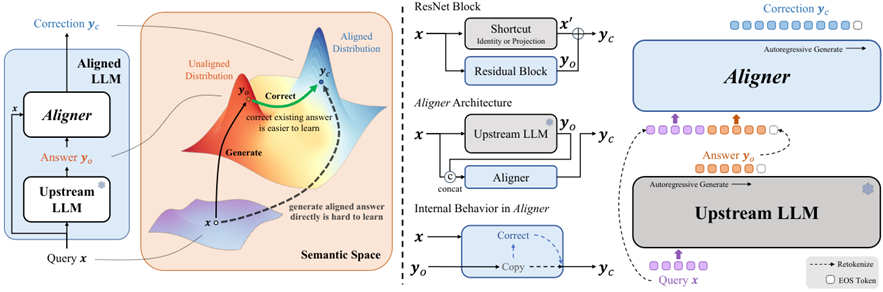
Aligner (ArXiv 24 北大)
学习一个adapter,接收问题、LLM回答,输出修正后的回答
CoBB (ArXiv 24 Carnegie Mellon)
对LLM进行多次采样产生不同的推理,根据答案是否正确划分推理为正负集,匹配为若干正负对,通过ORPO训练校正模型
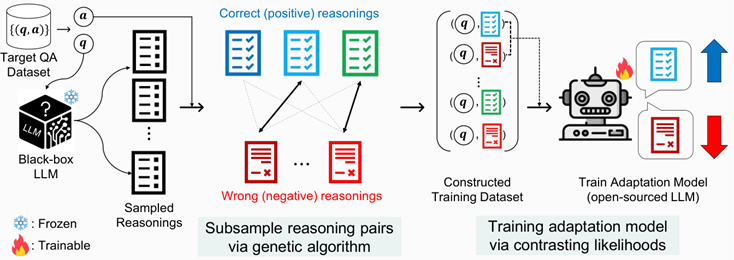
SuperContext (ICLR 24 西湖)
将fine-tune SLM的预测整合到LLM输入中,提升OOD泛化能力和减轻幻觉
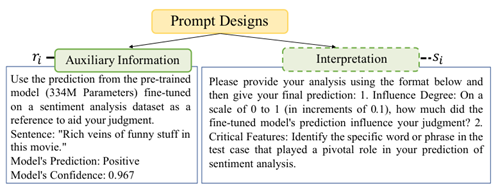
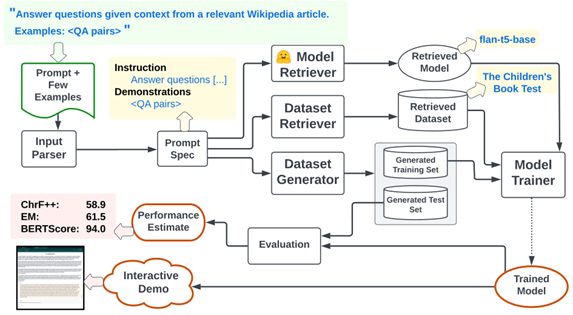
Prompt2model (ArXiv 24)
给定prompt和example,通过LLM选择微调模型、检索和生成数据,接着微调模型以适应特定任务
边缘微调
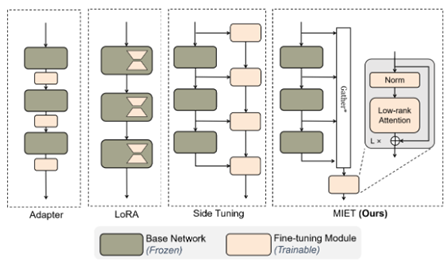
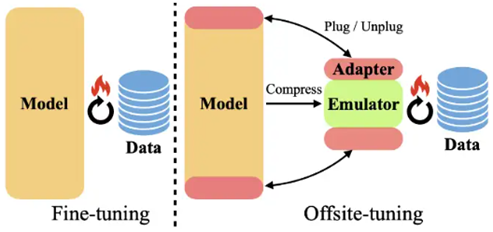
Offsite-Tuning (ArXiv 23 MIT) (EMNLP 23 清华)
通过压缩模型得到一个模拟器,之后添加adapter进行微调,最后将adapter添加到原模型上
MIET (ArXiv 24 Lamda)
将预训练模型作为服务端,在客户端学习一个小网络,在最小化服务端到客户端通信开销的前提下进行调整