引言
1. 随着大模型的发展和数据量的不断增加,预训练大模型逐渐拥有作为 “世界模型” 的潜力
2. 现有工作逐渐从从头训练模型,转为大模型的 适配 ,以及 推理 时的 免训练 增强
3. 比起学习新知识, 利用和激发预训练大模型 的知识成为新的热点
方法
自主构造数据
Learning by Correction (CVPR 24)
通过词法分析构造错误答案和纠正方式,微调模型以提高泛化能力
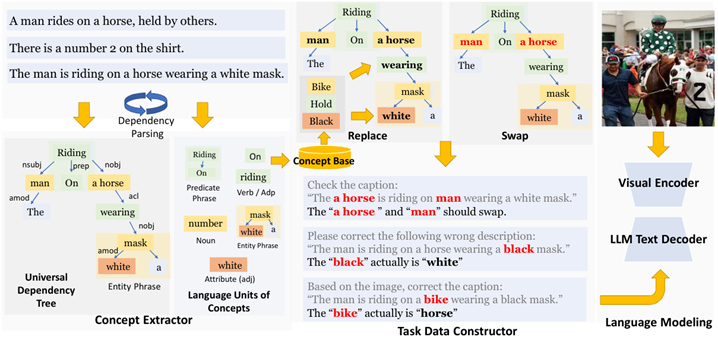
List Items One by One (COLM 24 UCSD, Microsoft)
提出逐一列出图像中物体的全新任务,并利用开放词汇检测器构造带密集注释的数据集

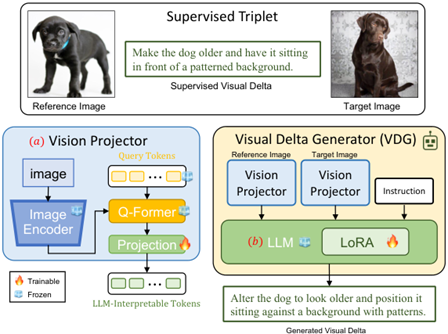
Visual Delta Generator (CVPR 24 Meta)
学习一个生成两张图像差异的VLM,自动化构造组合检索任务的训练数据集
总结:
任务设计上:一种是 自定义代理任务 ,并认为这种代理任务对下游任务有所帮助;一种是某个 特定的下游任务
数据构造上:一种是 提示模型自身 ;一种是 结合外部工具 ,如目标检测器、分割器等
对比解码
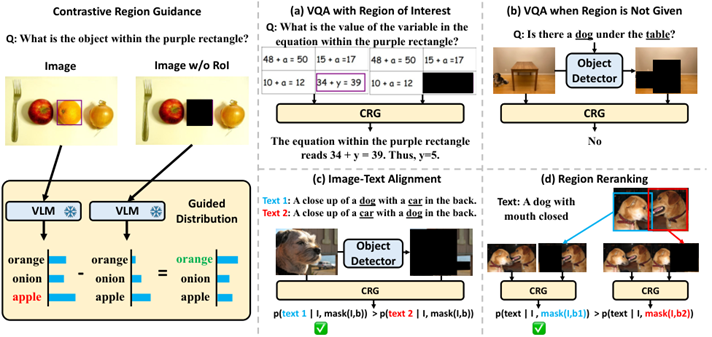
Contrastive Region Guidance (ECCV 24 UNC)
通过掩码前后图像的对比增强定位能力
视觉提示
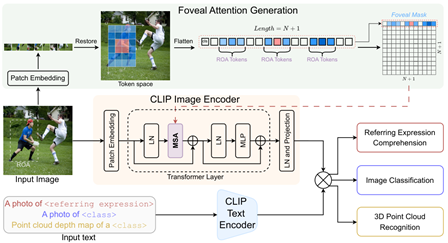
FALIP (ECCV 24)
一种视觉提示方法,将关注区域转换为高斯分布并展平,嵌入到注意力图的cls行中,实现对目标区域的关注
启发式设计
Rephrase, Augment, Reason (ICLR 24)
获取关键词、目标和图像描述,利用LLM重述问题以精准预测
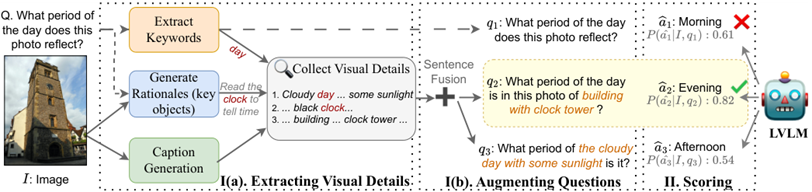
Chain of Symbol (COLM 24 西湖)
用浓缩符号取代文字,用更少的token提升性能

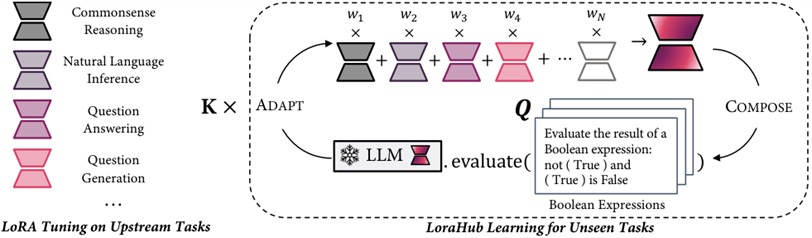
LoRAHub (COLM 24)
搜索一组已知任务上学习的LoRA在未知任务上权重的线性组合
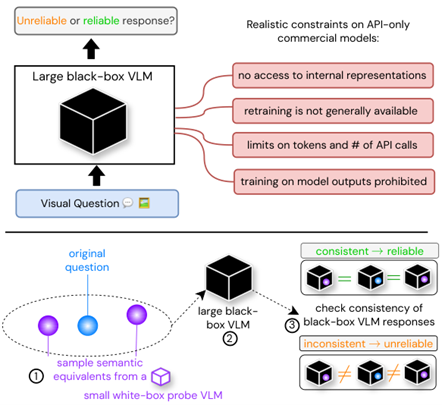
Consisitency and Uncertainty (CVPR 24)
学习小模型生成原问题的近似问题,评估黑盒大模型回答的一致性
总结
在基于预训练大模型的范式中, 强大的预训练模型 是最重要的,所有范式的关键都在于 利用预训练知识 ,而不是学习新知识
上述范式通常非常直观,不存在深入的 理论 知识
因此,上述范式的重点通常是探索 有趣的问题 (幻觉、效率、公平性等)或 特定下游任务 (定位、组合检索等),而不是对适配过程进行深入的研究