探索基于VLM的Embodied AI
VLM的发展
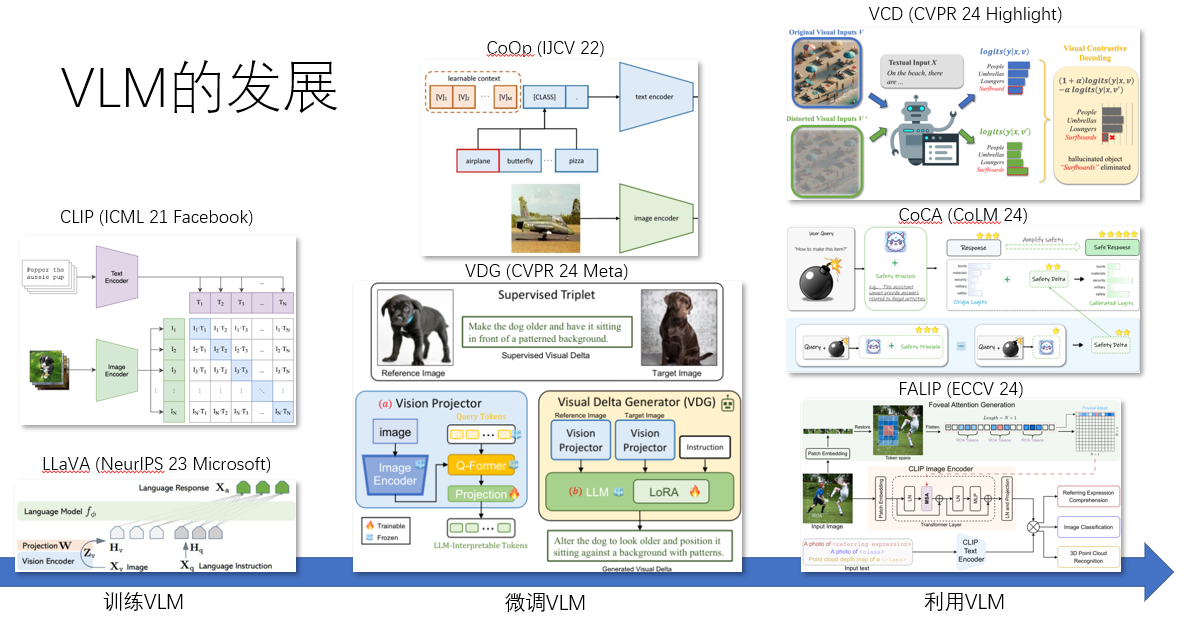
将VLM视为拥有大量知识的“世界模型”和通用助手
从通用任务的涨点转向特定问题和任务的探索
VLM 与 Embodied AI 的共同挑战

数据集
场景基准理解
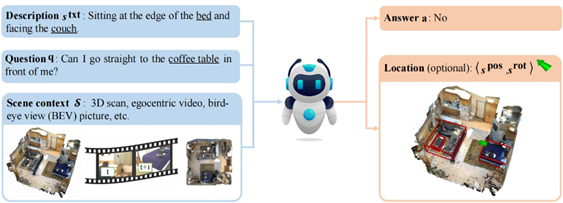
SQA3D (ICLR 23 UCLA):3D场景问答
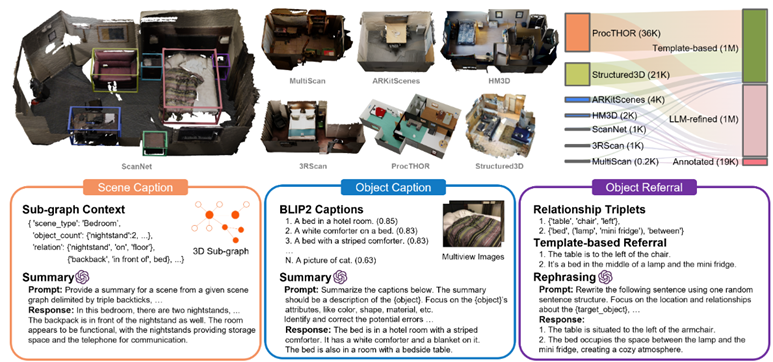
SceneVerse (ArXiv 24 BIGAI):3D场景的多层次细粒度描述
操作策略与规划
Behavior-1K (ArXiv 24 Stanford):大量动作、真实场景和物体

ManiSkill2 (ICLR 23)
ManiSkill3 (ArXiv 24 USCD):多种机器人、任务、类别和场景

注:针对序列、复杂任务,这类数据集可能会简化抓取为“吸取”,降低了操作难度
细粒度操作
Meta-World (CoRL 19)
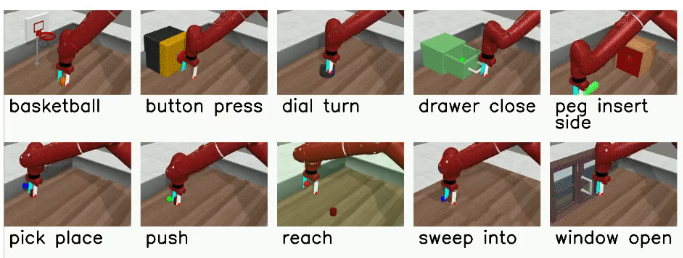
RLBench (RA-L 20 Google)

评测
Embodied Agent Interface (NeurIPS 24 Stanford):以往的评估仅针对最终成功率,提出一种分步的细粒度全面评估基准:
目标解释 :将自然语言目标转换为可能的目标、状态和动作
子任务分解 :将目标分解为一系列子任务
动作序列 :生成子任务间的一系列动作
转换建模 :执行动作完成状态转换
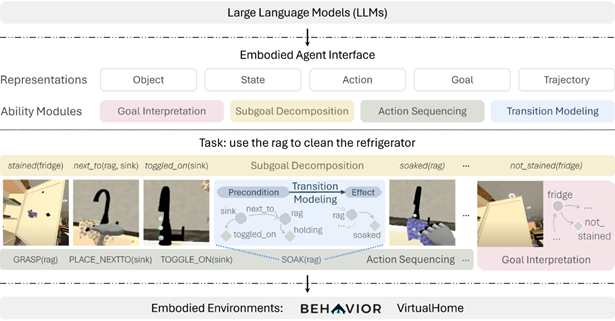
方法
场景基准理解
依靠RGB无法理解深度:机械臂抓到抹布了吗?
SpatialBot (ArXiv 24 Stanford):将深度信息融入VLM,基于深度推理任务训练

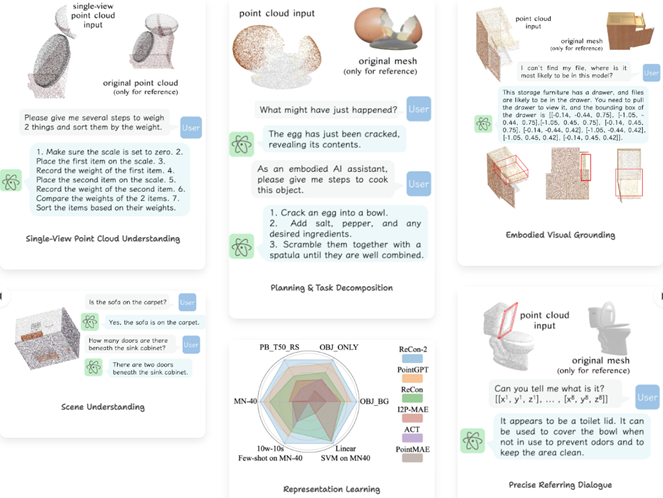
ShapeLLM (ECCV 24):基于3D点云和语言的多模态大模型,支持点云理解、任务规划、物体定位、场景理解等任务
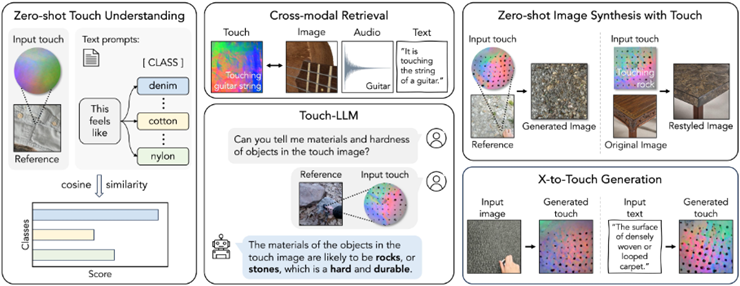
UniTouch (CVPR 24):视觉-触觉大模型,支持触觉检索、触觉推理、触觉到图像生成、图像/文本到触觉生成
高层次规划
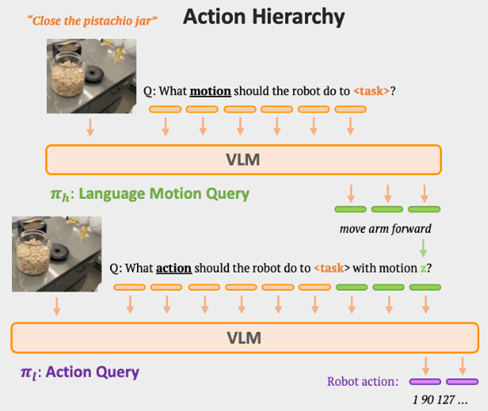
RT-H (ArXiv 24 Google):基于VLM先进行任务分解,再根据分解子任务预测动作
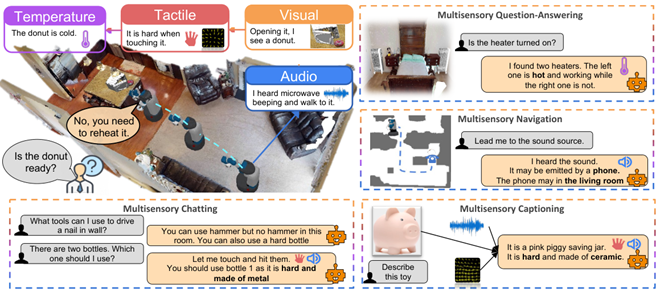
MultiPLY (CVPR 24 UCLA):提出一个场景感知数据集,包含声音、触觉、温度等
提出自我观察和多感知的大模型,将不同的感知信息整合到模型中,模型主动探索收集信息,再整合信息以生成后续操作
细粒度操作
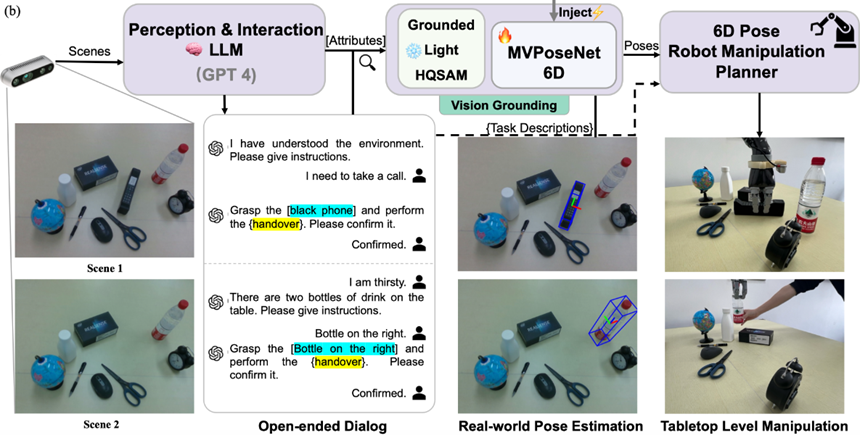
Polaris (IROS 24):预测物体姿势辅助机械臂操作
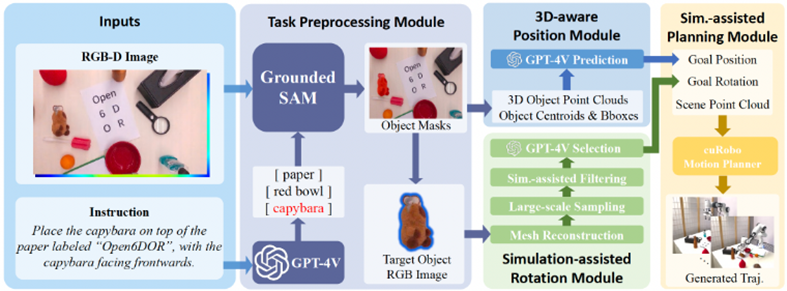
Open6DoR (IROS 24 Oral):专注于细粒度任务的精确执行
利用SAM分割物体
利用VLM预测目标位置
3D重建和物理模拟稳定的目标姿态,计算目标旋转
利用ASGrasp生成当前物体的候选抓握姿势
调用启发式工具执行动作
总结
机器人领域关注复杂的模态输入,如视觉(2D、3D、深度)、听觉、触觉等都可能是行动的依据
评测基准较缺乏,指标单一,无法对任务失败的具体原因进行溯源,同时缺乏对安全、可靠性、效率等指标的评估
任务分解和规划是通用大模型最擅长的领域,是最容易将视觉语言信息融入的部分,此外这部分benchmark不依赖现实中的机器人