Publications
Policy Contrastive Decoding for Robotic Foundation Models
Shihan Wu*, Ji Zhang*, Xu Luo, Junlin Xie, Jingkuan Song, Heng Tao Shen, Lianli Gao
Robotic foundation models, or generalist robot policies, hold immense potential to enable flexible, general-purpose and dexterous robotic systems. Despite their advancements, our empirical experiments reveal that existing robot policies are prone to learning spurious correlations from pre-training trajectories, adversely affecting their generalization capabilities beyond the training data.
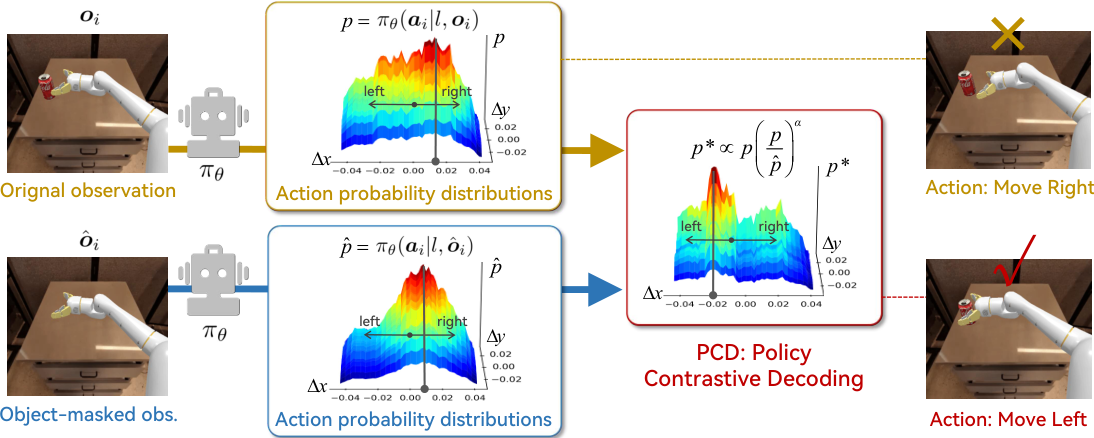
To tackle this, we propose a novel Policy Contrastive Decoding (PCD) approach, which redirects the robot policy's focus toward object-relevant visual clues by contrasting action probability distributions derived from original and object-masked visual inputs. As a training-free method, our PCD can be used as a plugin to improve different types of robot policies without needing to finetune or access model weights.
We conduct extensive experiments on top of three open-source robot policies, including the autoregressive policy OpenVLA and the diffusion-based policies Octo and . The obtained results in both simulation and real-world environments prove PCD's flexibility and effectiveness, e.g., PCD enhances the state-of-the-art policy by 8% in the simulation environment and by 108% in the real-world environment.
[Project Page] [PDF] [arXiv] [Code]

InSpire: Vision-Language-Action Models with Intrinsic Spatial Reasoning
Ji Zhang*, Shihan Wu*, Xu Luo, Hao Wu, Lianli Gao, Heng Tao Shen, Jingkuan Song
Leveraging pretrained Vision-Language Models (VLMs) to map language instruction and visual observations to raw low-level actions, Vision-Language-Action models (VLAs) hold great promise for achieving general-purpose robotic systems. Despite their advancements, existing VLAs tend to spuriously correlate task-irrelevant visual features with actions, limiting their generalization capacity beyond the training data.
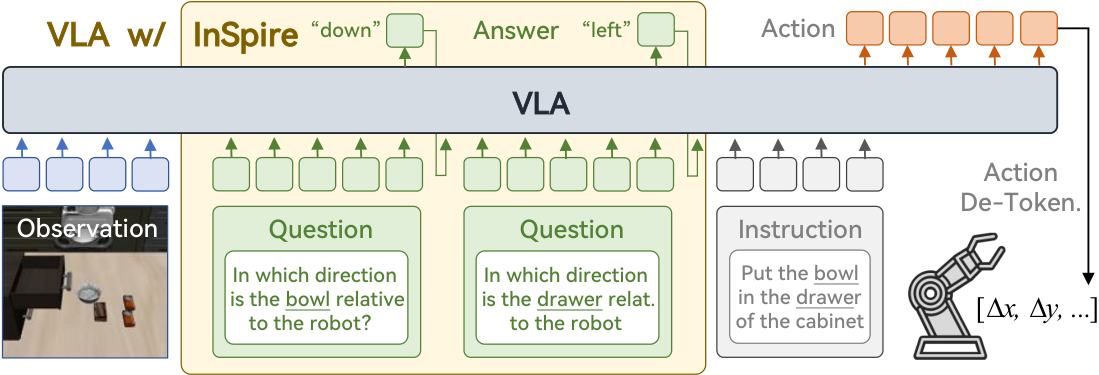
To tackle this challenge, we propose Intrinsic Spatial Reasoning (InSpire), a simple yet effective approach that mitigates the adverse effects of spurious correlations by boosting the spatial reasoning ability of VLAs. Specifically, InSpire redirects the VLA's attention to task-relevant factors by prepending the question "In which direction is the [object] relative to the robot?" to the language instruction and aligning the answer "right/left/up/down/front/back/grasped" and predicted actions with the ground-truth.
Notably, InSpire can be used as a plugin to enhance existing autoregressive VLAs, requiring no extra training data or interaction with other large models. Extensive experimental results in both simulation and real-world environments demonstrate the effectiveness and flexibility of our approach.
[Project Page] [PDF] [arXiv] [Code]

[CVPR 2025] Skip Tuning: Pre-trained Vision-Language Models are Effective and Efficient Adapters Themselves
Shihan Wu, Ji Zhang, Pengpeng Zeng, Lianli Gao, Jingkuan Song, Heng Tao Shen
Prompt tuning (PT) has long been recognized as an effective and efficient paradigm for transferring large pre-trained vision-language models (VLMs) to downstream tasks by learning a tiny set of context vectors. Nevertheless, in this work, we reveal that freezing the parameters of VLMs during learning the context vectors neither facilitates the transferability of pre-trained knowledge nor improves the memory and time efficiency significantly.
Upon further investigation, we find that reducing both the length and width of the feature-gradient propagation flows of the full fine-tuning (FT) baseline is key to achieving effective and efficient knowledge transfer. Motivated by this, we propose Skip Tuning, a novel paradigm for adapting VLMs to downstream tasks. Unlike existing PT or adapter-based methods, Skip Tuning applies Layer-wise Skipping (LSkip) and Class-wise Skipping (CSkip) upon the FT baseline without introducing extra context vectors or adapter modules.
Extensive experiments across a wide spectrum of benchmarks demonstrate the superior effectiveness and efficiency of our Skip Tuning over both PT and adapter-based methods.


Rethinking Conditional Prompt Tuning for Vision-Language Models
Ji Zhang, Shihan Wu, Pengpeng Zeng, Lianli Gao, Jingkuan Song, Heng Tao Shen
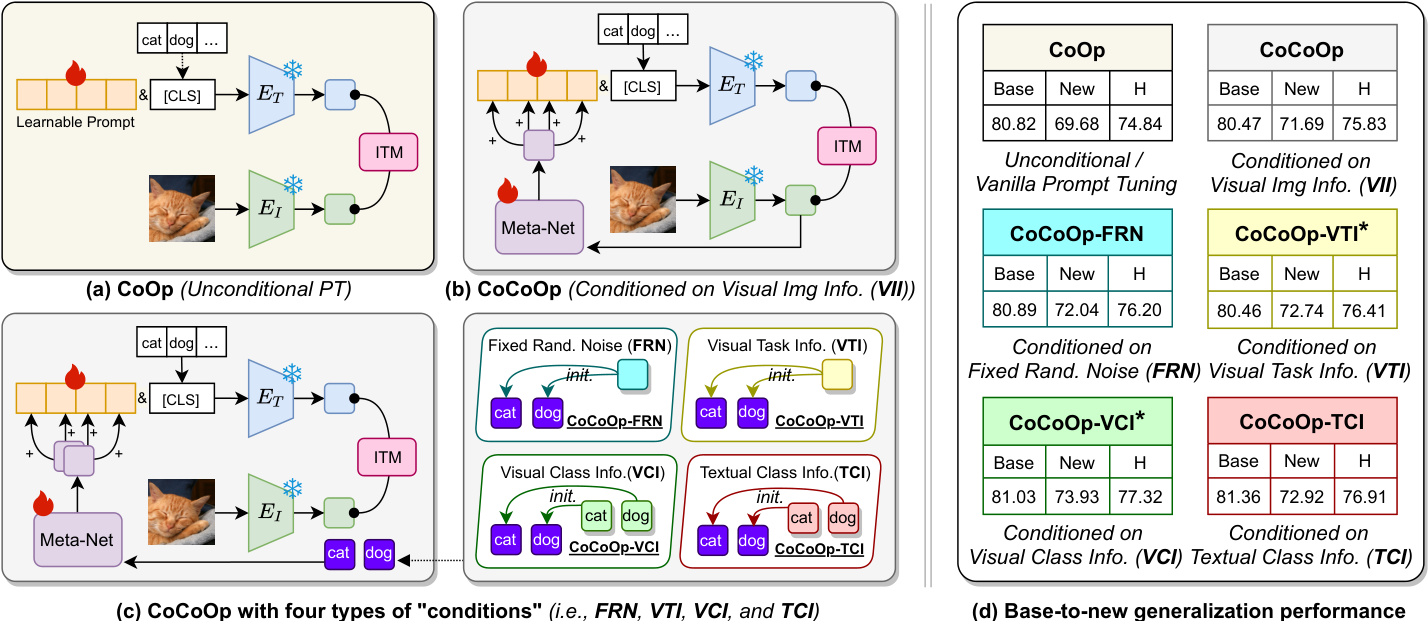
Prompt tuning has demonstrated remarkable success in adapting large Vision-Language pretrained Models (VLPMs) to a variety of downstream tasks. Despite the great promise, existing prompt learning methods often struggle to overcome the Base-New Tradeoff (BNT) problem, i.e. as VLPMs are better tuned to a base (or target) task, their ability to generalize to new tasks diminishes. Recent work on conditional prompt learning addresses this problem by replacing static prompts with dynamic Visual Image Information (VII)-conditioned prompts, improving the model’s generalization to new tasks to some extent.
In this work, we identify a critical issue with existing conditional prompt tuning approaches: the performance gains on new tasks do not benefit from the VII injected into the prompt. In fact, even a random noise-conditioned prompt can outperform the VII-conditioned counterpart. On further analysis, we find that learning dynamic prompts conditioned on Textual Class Information (TCI) is the key to solving the BNT problem in prompt tuning. Motivated by this, we propose **Class-adaptive Prompt Tuning (CaPT), which enables fast adaptation of tuned models to new classes by learning TCI-conditioned prompts from the base task classes.
Notably, our CaPT is orthogonal to existing unconditional prompt tuning approaches and can be used as a plugin to enhance them with negligible additional computational cost. Extensive experiments on several datasets show the strong flexibility and effectiveness of CaPT. CaPT consistently improves the performance of a broad spectrum of prompt tuning methods across base-to-new generalization, cross-dataset generalization and cross-domain generalization settings.

[CVPR 2024] DePT: Decoupled Prompt Tuning
Ji Zhang*, Shihan Wu*, Lianli Gao, Heng Tao Shen, Jingkuan Song
Prompt tuning has shown great success in adapting large vision-language pre-trained models to downstream tasks. A plethora of methods have been proposed to tackle the base- new tradeoff (BNT) dilemma, i.e., the better the adapted model generalizes to the base (a.k.a. target) task, the worse it generalizes to new tasks, and vice versa. Despite this, the BNT problem is still far from being resolved and its underlying mechanisms are poorly understood.
In this work, we bridge this gap by proposing Decoupled Prompt Tuning (DePT), a first framework tackling the BNT problem from a feature decoupling perspective. Specifically, through an in-depth analysis on the learned features of the base and new tasks, we observe that the BNT stems from a channel bias issue, i.e., the vast majority of feature channels are occupied by base-specific knowledge, resulting in the collapse of task-shared knowledge important to new tasks. To address this, DePT decouples base-specific knowledge from feature channels into an isolated feature space during prompt tuning, so as to maximally preserve task-shared knowledge in the original feature space for achieving better zero-shot generalization on new tasks.
DePT is orthogonal to existing prompt tuning methods, hence it can tackle the BNT problem for all of them. Extensive experiments on 11 datasets show the strong flexibility and effectiveness of DePT.

