发表论文
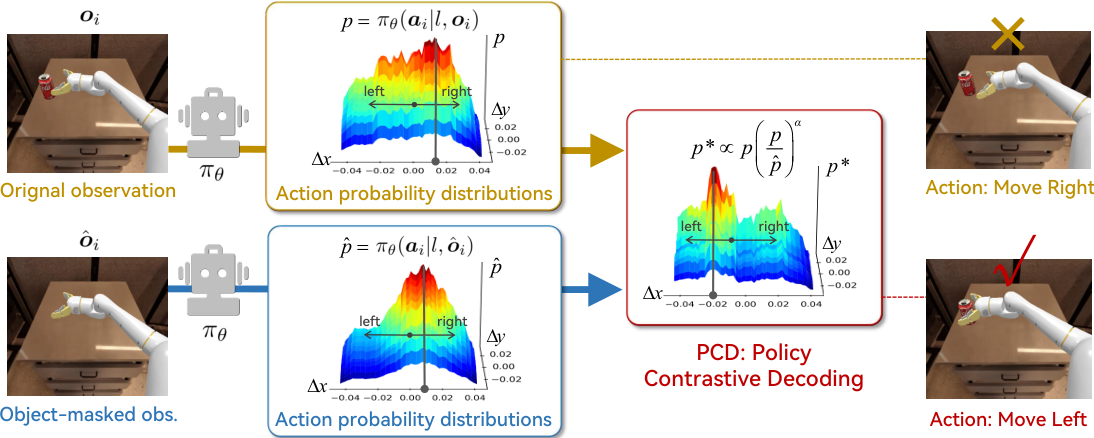
Policy Contrastive Decoding for Robotic Foundation Models
Shihan Wu*, Ji Zhang*, Xu Luo, Junlin Xie, Jingkuan Song, Heng Tao Shen, Lianli Gao
机器人基础模型,或通用机器人策略,具有实现灵活、通用和灵巧机器人系统的巨大潜力。尽管它们取得了进展,但我们的实验证明,现有的机器人策略容易从预训练轨迹中学习到虚假相关性,从而影响其在训练数据范围之外的泛化能力。
为了解决这个问题,我们提出了一种新颖的策略对比解码(PCD)方法,通过对比源视觉输入和对象遮蔽视觉输入的动作概率分布,将机器人策略的注意力重定向到与对象相关的视觉线索上。作为一种无需训练的方法,我们的PCD可以作为插件来改进不同类型的机器人策略,而无需微调或访问模型权重。
我们在三个开源机器人策略上进行了广泛的实验,包括自回归策略OpenVLA和基于扩散的策略Octo和。实验结果证明了PCD在模拟和现实环境中的灵活性和有效性,例如,PCD在模拟环境中提高了最先进的策略8%,在现实环境中提高了108%。

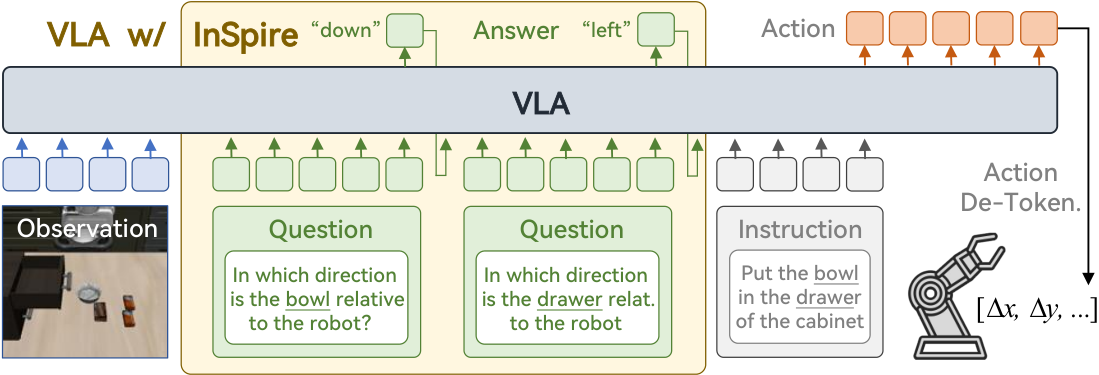
InSpire: Vision-Language-Action Models with Intrinsic Spatial Reasoning
Ji Zhang*, Shihan Wu*, Xu Luo, Hao Wu, Lianli Gao, Heng Tao Shen, Jingkuan Song
利用预训练的视觉语言模型(VLMs)将语言指令和视觉观察映射到原始低级动作,视觉语言动作模型(VLAs)有望实现通用机器人系统。尽管取得了进展,但现有的VLA往往会将与任务无关的视觉特征与动作虚假关联,从而限制了其在训练数据之外的泛化能力。
为了解决这个挑战,我们提出了内在空间推理(InSpire),这是一种简单而有效的方法,通过增强VLA的空间推理能力来减轻虚假相关性的负面影响。具体而言,InSpire通过在语言指令前添加问题“[对象]相对于机器人处于哪个方向?”来将VLA的注意力重定向到与任务相关的因素,并将答案“右/左/上/下/前/后/抓取”和预测动作与地面真实值对齐。
值得注意的是,InSpire可以作为插件来增强现有的自回归VLA,无需额外的训练数据或与其他大型模型交互。模拟和现实环境中的广泛实验结果证明了我们方法的有效性和灵活性。

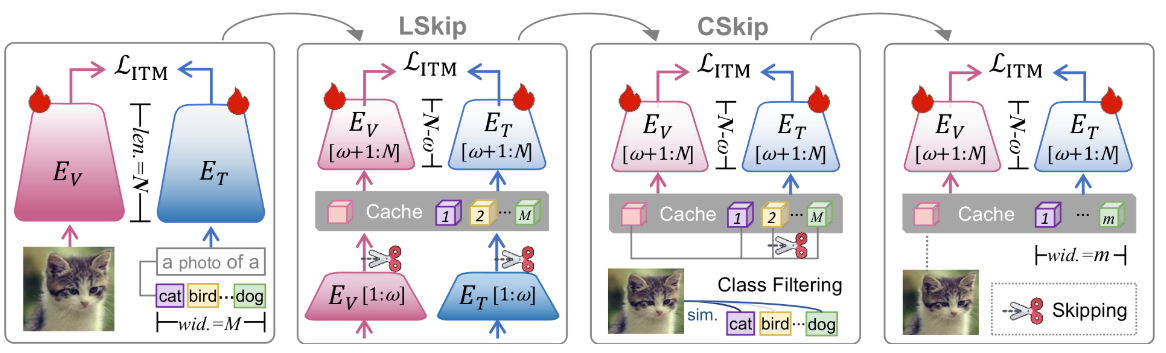
[CVPR 2025] Skip Tuning: Pre-trained Vision-Language Models are Effective and Efficient Adapters Themselves
Shihan Wu, Ji Zhang, Pengpeng Zeng, Lianli Gao, Jingkuan Song, Heng Tao Shen
提示调优(PT)长期以来被认为是将大型预训练视觉语言模型(VLMs)转移到下游任务的有效和高效范式,通过学习一小组上下文向量。然而,在这项工作中,我们揭示了在学习上下文向量时冻结VLMs的参数既不能促进预训练知识的可转移性,也不能显著提高内存和时间效率。
经过进一步调查,我们发现减少全量微调(FT)基线的特征梯度传播流的长度和宽度是实现有效和高效知识转移的关键。基于此,我们提出了Skip Tuning,这是一种适应VLMs到下游任务的新范式。与现有的PT或基于适配器的方法不同,跳过调优在FT基线上应用了层级跳过(LSkip)和类级跳过(CSkip),而不引入额外的上下文向量或适配器模块。
广泛的实验结果表明,我们的跳过调优在各种基准测试中表现出优越的有效性和效率,超过了PT和基于适配器的方法。

Rethinking Conditional Prompt Tuning for Vision-Language Models
Ji Zhang, Shihan Wu, Pengpeng Zeng, Lianli Gao, Jingkuan Song, Heng Tao Shen
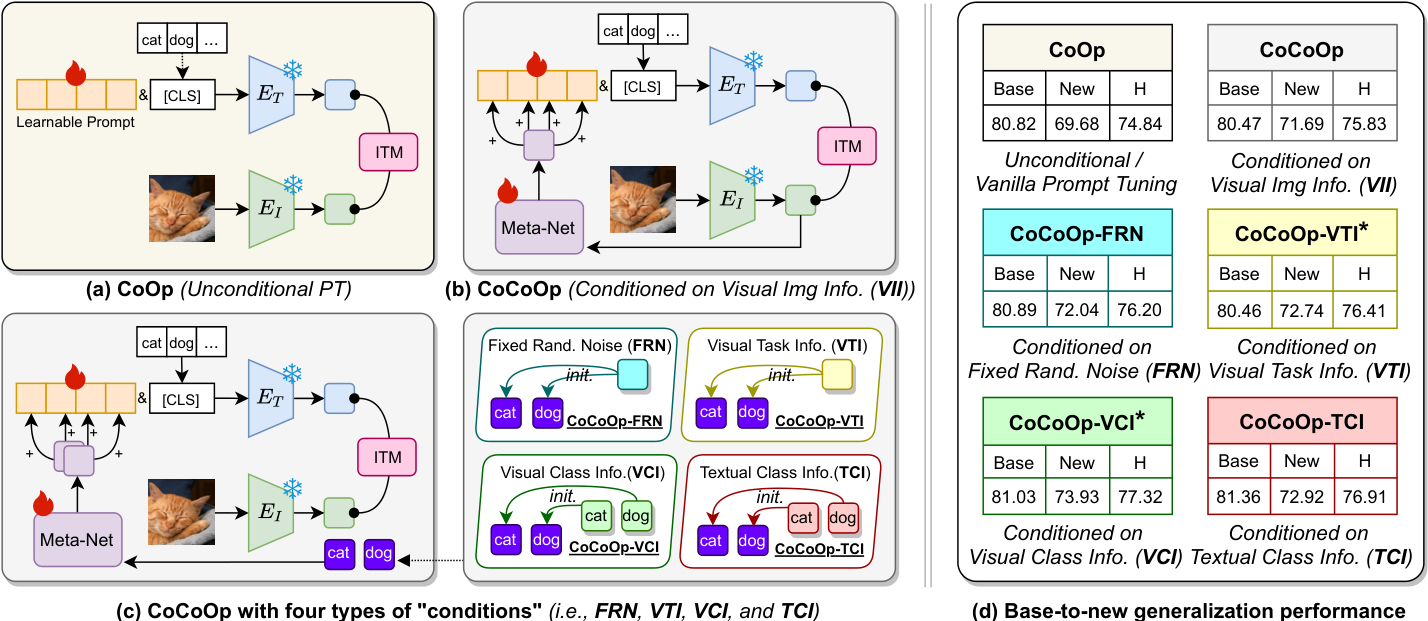
提示调优在将大型视觉语言预训练模型(VLPMs)适应到各种下游任务方面表现出色。尽管前景广阔,但现有的提示学习方法往往难以克服基础-新任务权衡(BNT)问题,即当VLPMs更好地适应基础(或目标)任务时,它们对新任务的泛化能力会降低。最近的条件提示学习工作通过用动态的视觉图像信息(VII)条件提示替换静态提示来解决这个问题,在一定程度上提高了模型对新任务的泛化能力。
在这项工作中,我们发现现有条件提示调优方法存在一个关键问题:新任务上的性能提升并没有受益于注入到提示中的VII。事实上,即使是随机噪声条件的提示也可以超过VII条件的对应物。进一步分析发现,学习基于文本类信息(TCI)的动态提示是解决提示调优中的BNT问题的关键。基于此,我们提出了类自适应提示调优(CaPT),它通过从基础任务类中学习TCI条件的提示,使调优模型能够快速适应新类。
值得注意的是,我们的CaPT与现有的无条件提示调优方法是正交的,可以作为插件来增强它们,而几乎不增加额外的计算成本。在多个数据集上的广泛实验表明了CaPT的强大灵活性和有效性。CaPT在基础到新任务泛化、跨数据集泛化和跨领域泛化设置中持续提高了广泛的提示调优方法的性能。

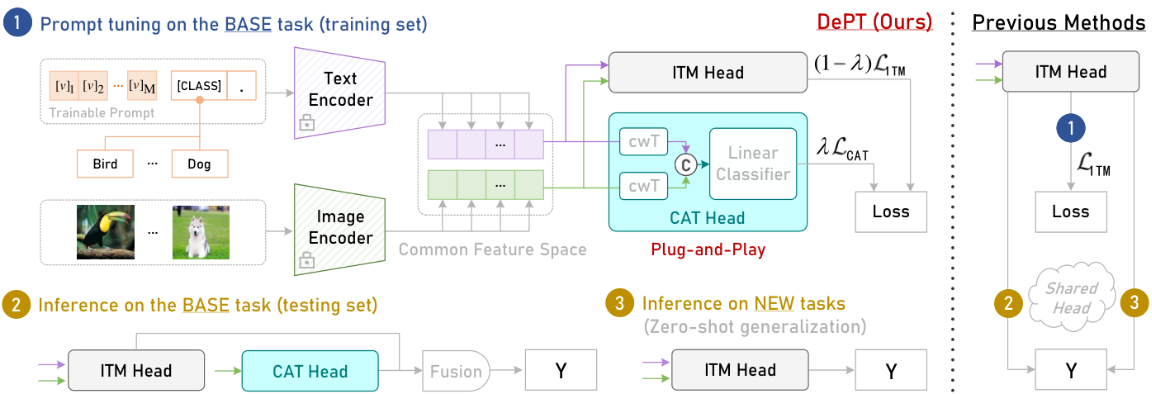
[CVPR 2024] DePT: Decoupled Prompt Tuning
Ji Zhang*, Shihan Wu*, Lianli Gao, Heng Tao Shen, Jingkuan Song
提示调优在将大型视觉语言预训练模型适应到下游任务方面取得了巨大的成功。已经提出了大量方法来解决基础-新任务权衡(BNT)困境,即适应后的模型对基础(或目标)任务的泛化越好,对新任务的泛化就越差,反之亦然。尽管如此,BNT问题仍然远未解决,其基本机制也不清楚。
在这项工作中,我们通过提出解耦提示调优(DePT)来填补这一空白,这是第一个从特征解耦的角度解决BNT问题的框架。具体而言,通过对基础和新任务的学习特征进行深入分析,我们观察到BNT源于通道偏置问题,即大多数特征通道被基础特定知识占据,导致对新任务重要的任务共享知识崩溃。为了解决这个问题,DePT在提示调优过程中将基础特定知识从特征通道中解耦到一个独立的特征空间,从而最大限度地保留原始特征空间中的任务共享知识,以实现对新任务更好的零样本泛化。
DePT与现有的提示调优方法是正交的,因此可以解决所有方法的BNT问题。在11个数据集上的广泛实验表明了DePT的强大灵活性和有效性。