从人类视频中学习机器人动作:人工设计与潜在动作
- 机器人策略的学习依赖大量机器人动作数据,而机器人数据收集成本极高
- 另一方面,人类动作视频中存在大量与机器人操作相似的规律
- 如何从人类视频中提供迁移到机器人的通用动作信息,成为重要问题
人工设计阶段
人工设计:图像编辑
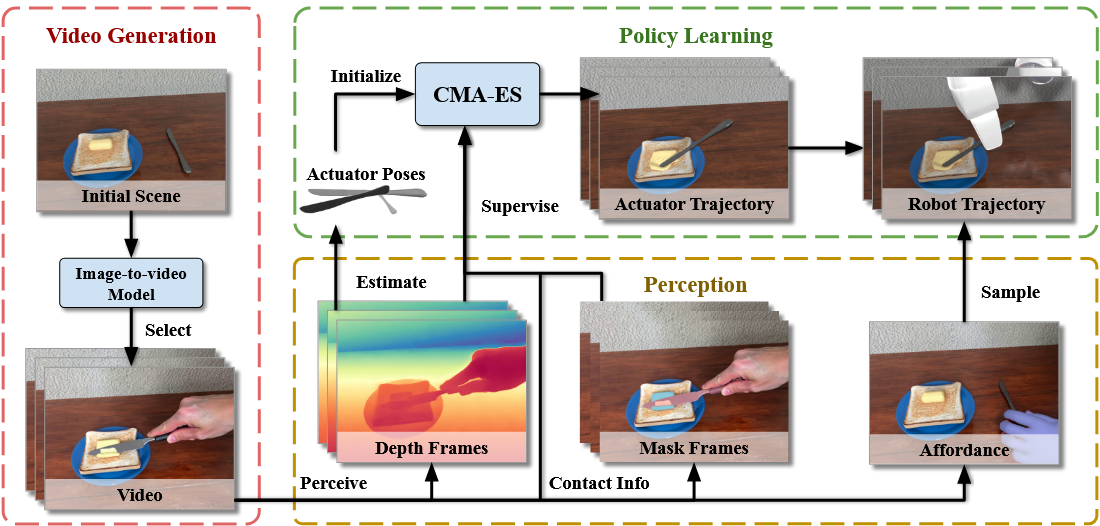 LuciBot通过密集的检测、分割、跟踪等方法,得到人手和操作物体的位置和运动轨迹,之后通过图像编辑将人手替换为机械臂,从而迁移到机器人数据
LuciBot通过密集的检测、分割、跟踪等方法,得到人手和操作物体的位置和运动轨迹,之后通过图像编辑将人手替换为机械臂,从而迁移到机器人数据
这种方法往往针对特定任务,且生成的视频不一定符合物理规律
人工设计:中间表示
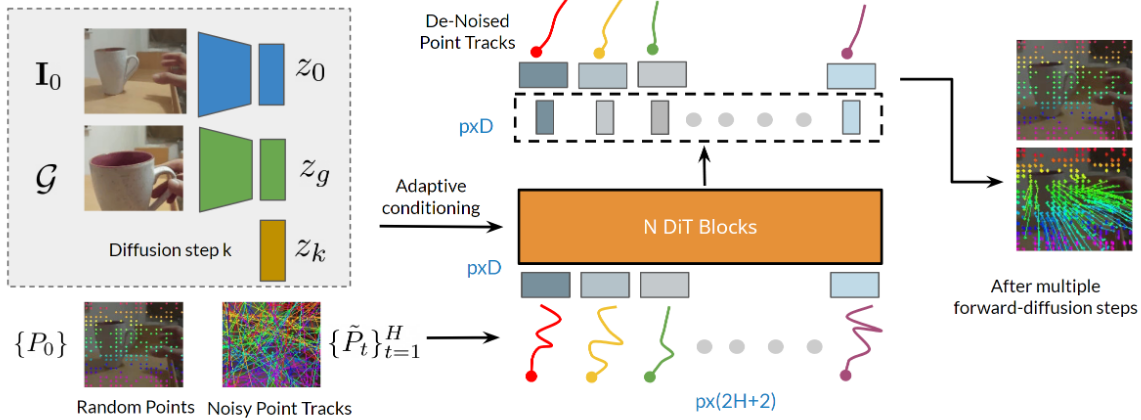 ATM/Track2Act/General
Flow等方法提出了一种中间表示:点跟踪轨迹/任务流,即视频中任务目标上随机点的运动轨迹,模型学习预测该轨迹之后预测动作
ATM/Track2Act/General
Flow等方法提出了一种中间表示:点跟踪轨迹/任务流,即视频中任务目标上随机点的运动轨迹,模型学习预测该轨迹之后预测动作
人工设计表示缺乏3D、手部姿势等信息,不可能面面俱到
潜在动作
人工设计存在各种缺陷,而潜在动作有希望学到与动作有关的各种规律,因此最近成为研究重点。为什么需要潜在动作?
- 学习跨不同环境、任务、智能体的动作表示能力。人工设计的方法不一定满足所有场景,如2D视频中难以标注3D空间信息,也难以满足形状各异的机器人
- 人工设计和标注问题。为特定任务设计特定监督需要大量成本,另外自动化标注也需要成本,且可能存在误差
- 学习更潜在规律的潜力。人工设计难以表示深层规律,如机械臂与物体的最佳相对角度和位置关系,物体操作的有关物体属性等,这些规律有可能在潜在动作中学到
Latent Action Pretraining from Videos (ICLR 24,微软/NVIDIA/Allen AI)
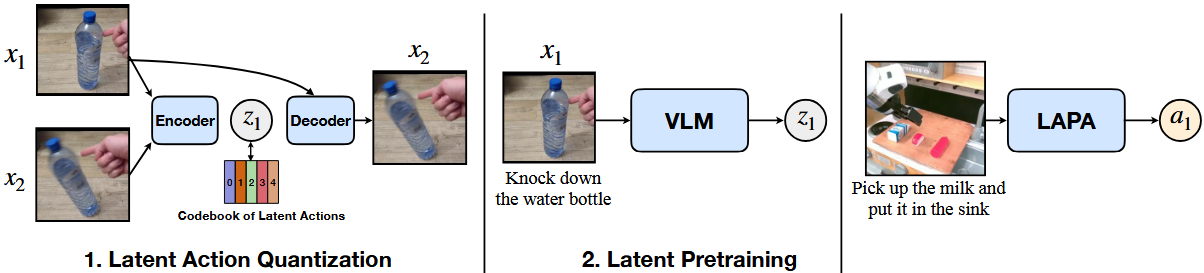
LAPA学习视频前后帧间的潜在关系作为潜在动作,具体步骤: 1. 学习人类视频潜在编码。设计一个VQ-VAE,encoder根据视频前后帧编码latent code,decoder依靠latent code预测未来帧 2. 预测潜在编码。VLM接收图像观察和文本,预测latent code 3. 预测动作。添加动作头,在机器人动作数据上微调,预测action
CoMo: Learning Continuous Latent Motion from Internet Videos for Scalable Robot Learning (25, 上海AI Lab)
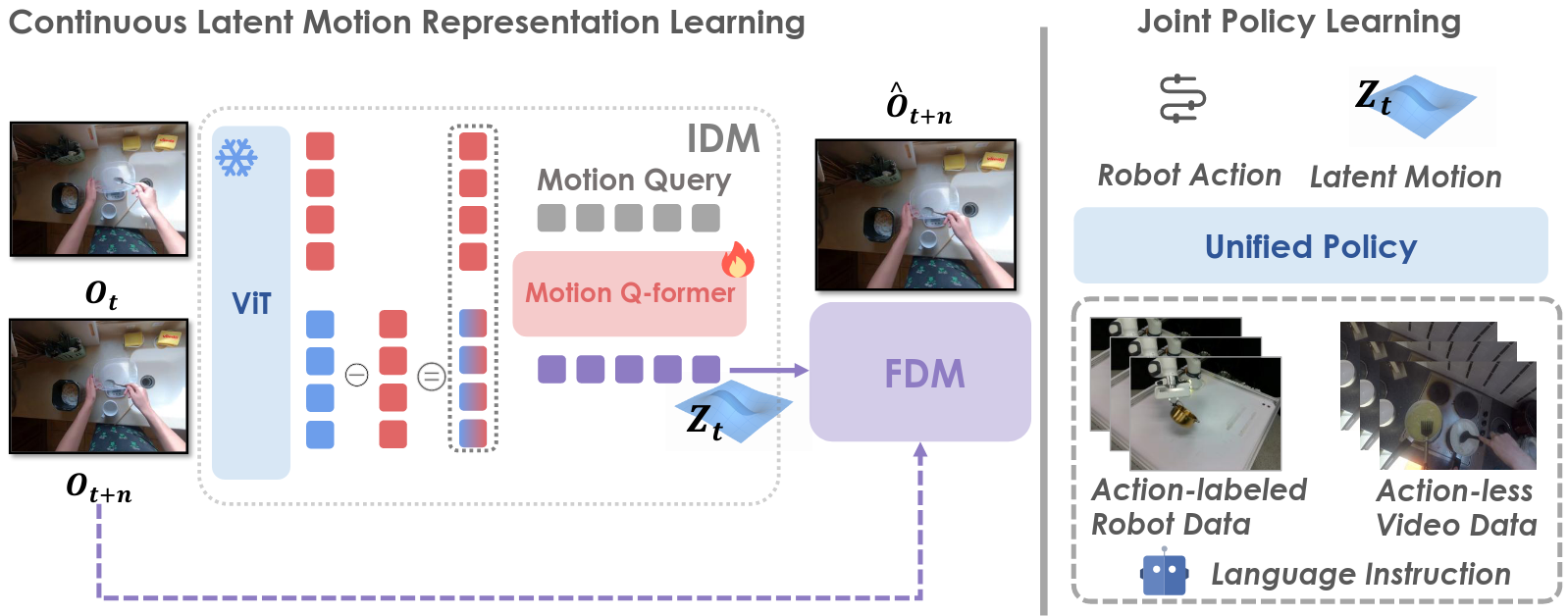
核心:从帧间特征差异中显式学习连续的潜在动作
CLAM: Continuous Latent Action Models for Robot Learning from Unlabeled Demonstrations (25, USC)
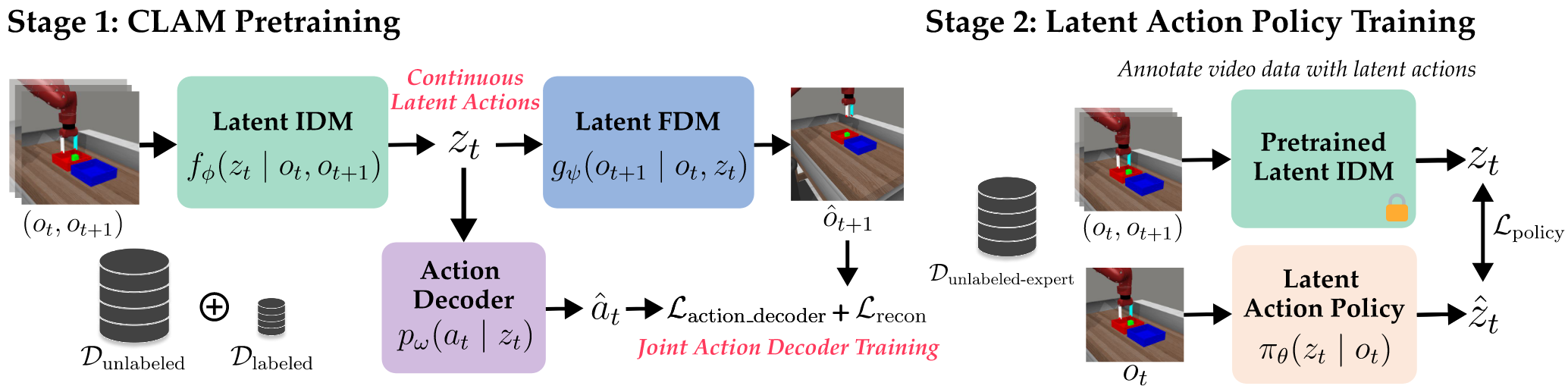
核心:学习动作相关的连续动作表示,利用大量非专家轨迹学习动作
- 从非专家标注数据中学习。给定有标注的非专家轨迹(可以是随机运动),编码器学习连续的latent action,FDM/动作解码器基于latent action预测未来帧和动作(如果有标注)
- 从无标注专家数据中学习。为无标注专家轨迹打上latent action标签,学习预测latent action的policy,通过非专家轨迹上训练的动作解码器得到动作
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions (RSS 25,OpenDriveLab/AgiBot)
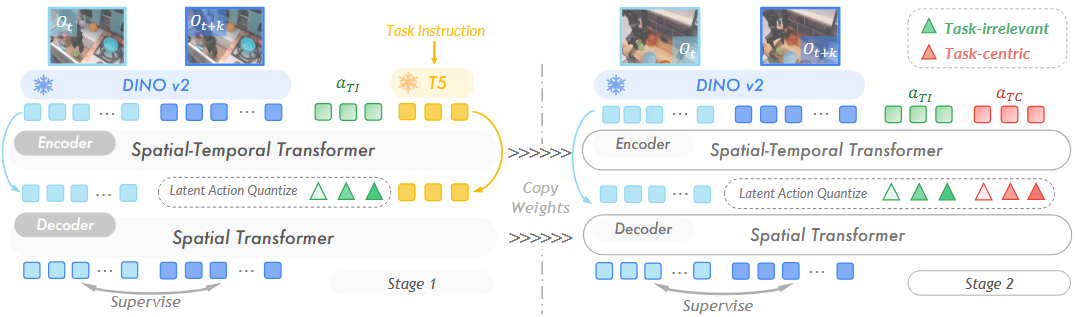
问题:视频中相机抖动、背景干扰等噪声淹没任务关键动态,LAPA虽尝试学习潜在动作,但未解耦任务相关/无关动态
核心:以任务为中心的潜在动作学习
- 任务无关表征学习。语言指令与任务无关token共同编码为latent,latent与语言指令一起预测未来帧。由于任务指令与任务的强相关性和任务无关token的有限容量,后者会倾向于学习跨任务不变的通用表征
- 任务特定表征学习。冻结任务无关token,加入新的可学习token,与任务无关token共同编码为latent action之后用于预测未来帧,这样可学习token专注于学习任务相关信息
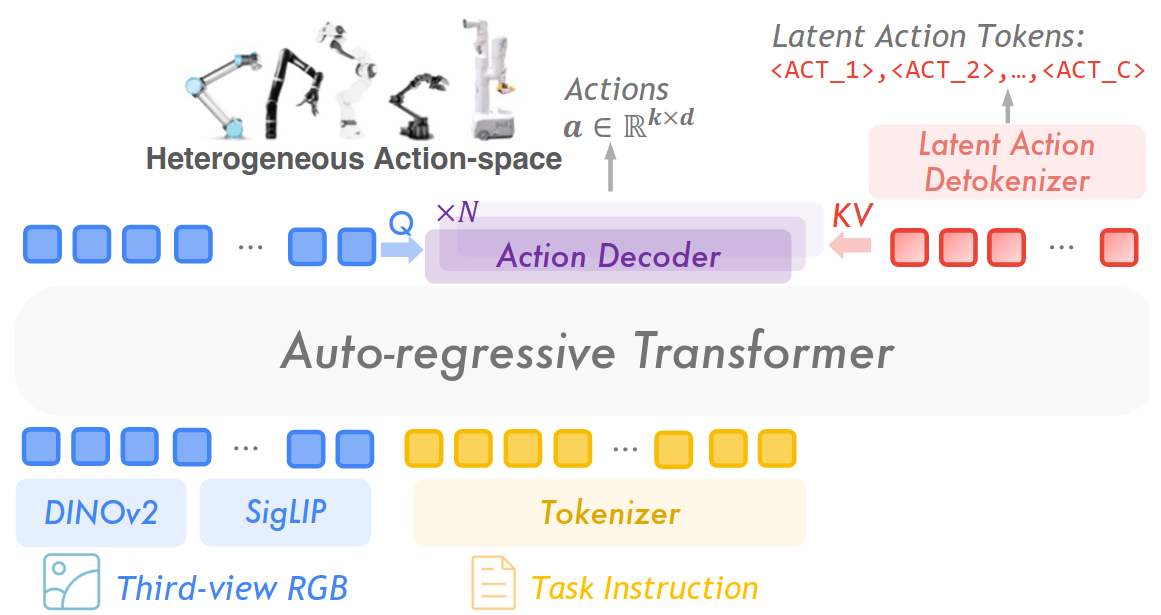
预测动作。下游policy学习预测任务相关latent action,预测的latent action与图像embedding一起通过交叉注意力预测action
潜在动作的下游应用
Moto: Latent Motion Token as the Bridging Language for Learning Robot Manipulation from Videos (25, Tencent/Berkeley)
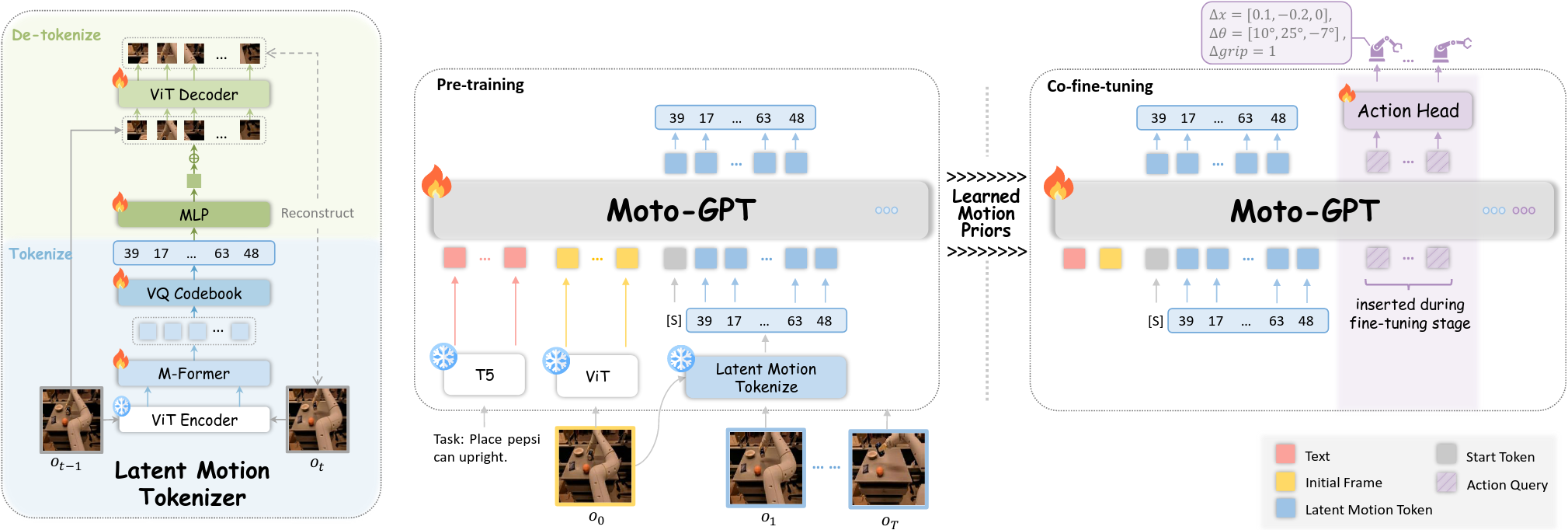
潜在动作用于中间监督,模型先预测latent action,再预测动作。latent action是更紧凑和通用的表示,因此可以作为到最终动作之前的过渡
DreamGen: Unlocking Generalization in Robot Learning through Neural Trajectories (25, NVIDIA/UCSD/Caltech)
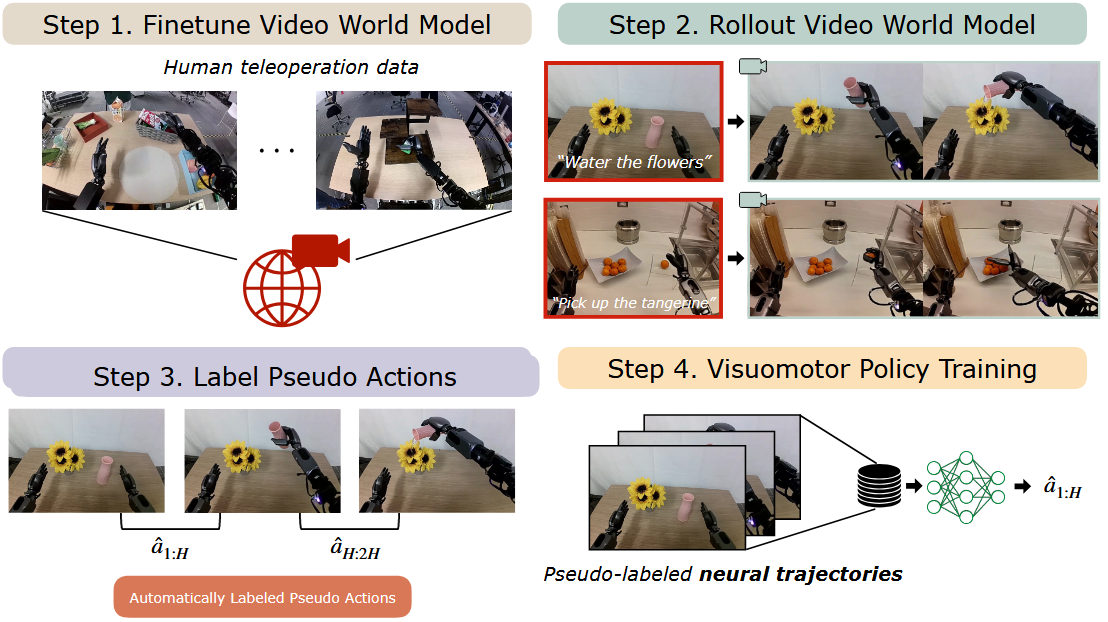
潜在动作用于数据标注
- 通过世界模型生成机器人操作视频
- 通过LAPA为相邻帧间生成伪动作标签
- 生成视频+伪标签与真机数据一起联合训练下游policy
Unified Video Action Model (25, Stanford)
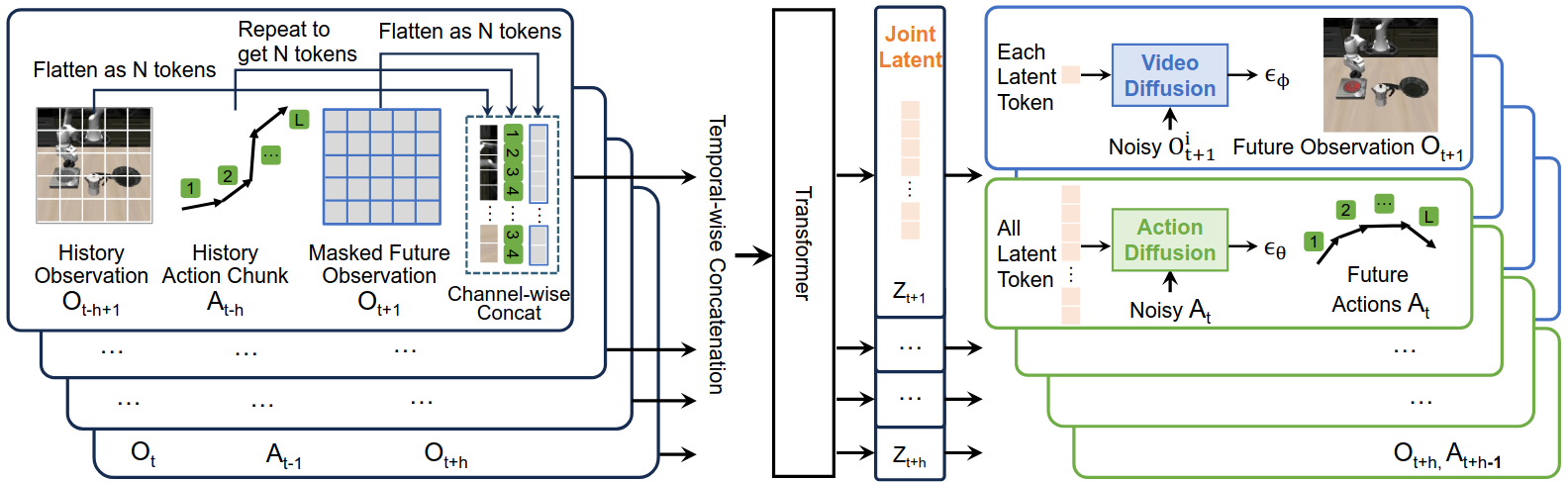
潜在动作用于学习世界模型。latent不仅可以编码视频,也可以编码动作,最终实现未来视频和动作的协同预测
总结
| 类别 | 代表工作 | 核心思想 | 关键特点 |
|---|---|---|---|
| 人工设计 | LuciBot | 视频编辑 | ⚠️ 特定任务|物理不合理 |
| Track2Act | 点轨迹作为动作 | ⚠️ 缺失3D信息|依赖标注 | |
| 潜在动作 | LAPA | 学习帧间变化 | 🔄 跨域迁移|细节不足 |
| CoMo | 连续向量编码运动差异 | ✅ 精细动作|连续控制 | |
| UniVLA | 分离任务相关/无关动态 | ✅ 抗干扰|强泛化 | |
| CLAM | 非专家数据学习动作 | ✅ 降低标注依赖 | |
| 应用扩展 | DreamGen | 生成视频+伪动作标签 | 💡 扩增数据|成本低 |
| UVAM | 统一预测未来帧+动作 | 💡 支持长时序规划 |
人工设计 vs 潜在动作
| 方法 | 思想 | 表示方式 | 完备性 | 泛化性 |
|---|---|---|---|---|
| 人工设计 | 人工定义表示 | 轨迹、光流等 | 缺失3D、物理等信息 | 局限于特定任务和智能体 |
| 潜在动作 | 可学习的表示 | 离散Token或连续向量 | 自主学习物理属性等深层规律 | 可在不同智能体、环境间泛化 |
从人类视频中学习机器人动作:人工设计与潜在动作
https://koorye.github.io/blog/2025/07/14/从人类视频中学习机器人动作:人工设计与潜在动作/