机器人轨迹的评价指标
新颖性
ThriftyDAgger: Budget-Aware Novelty and Risk Gating for Interactive Imitation Learning (CoRL 21 Oral, Berkeley)
- 通过对当前policy进行MC-Dropout,将当前状态
作为输入,得到动作集合 - 计算方差
- 该指标反映了对于当前state
,模型预测的不确定性
兼容性
Eliciting compatible demonstrations for multi-human imitation learning (CoRL 23, Stanford)
提出一种兼容性的指标: 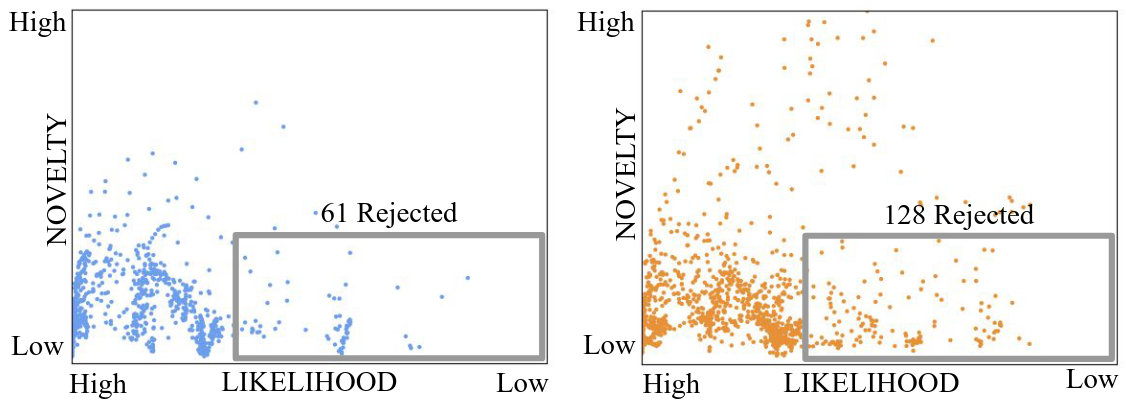
基于强化学习的奖励函数
VIP: Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training (ICLR 23 Spotlight, Meta AI)
通过隐式价值训练学习一个奖励函数的预测网络,该网络可以在人类视频上学习,之后zero-shot迁移到机器人运动视频上,实现轨迹评分或提供密集监督
具体来说,从人类视频序列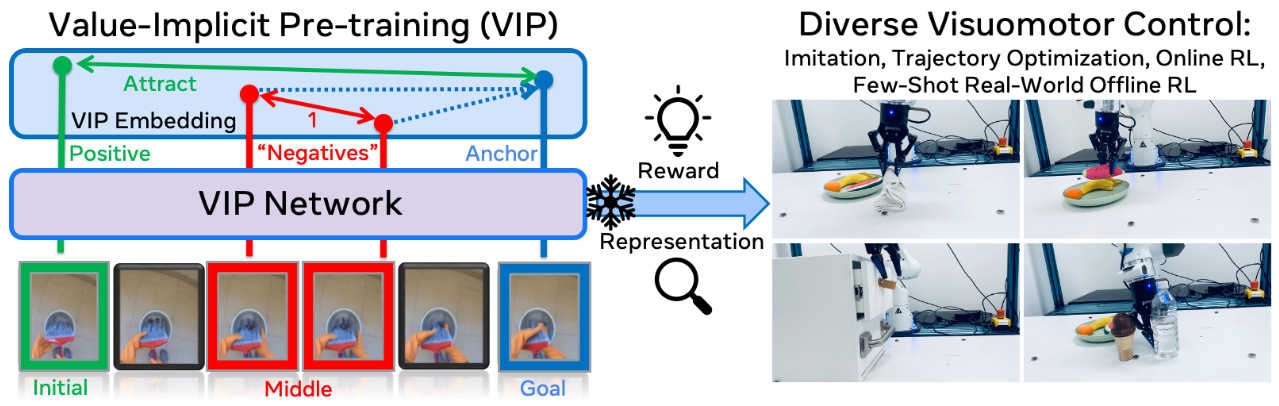 ### Rank2Reward: Learning Shaped
Reward Functions from Passive Video (ICRA 24, MIT) 学习两个目标:
专家分类函数:学习一个分类网络
### Rank2Reward: Learning Shaped
Reward Functions from Passive Video (ICRA 24, MIT) 学习两个目标:
专家分类函数:学习一个分类网络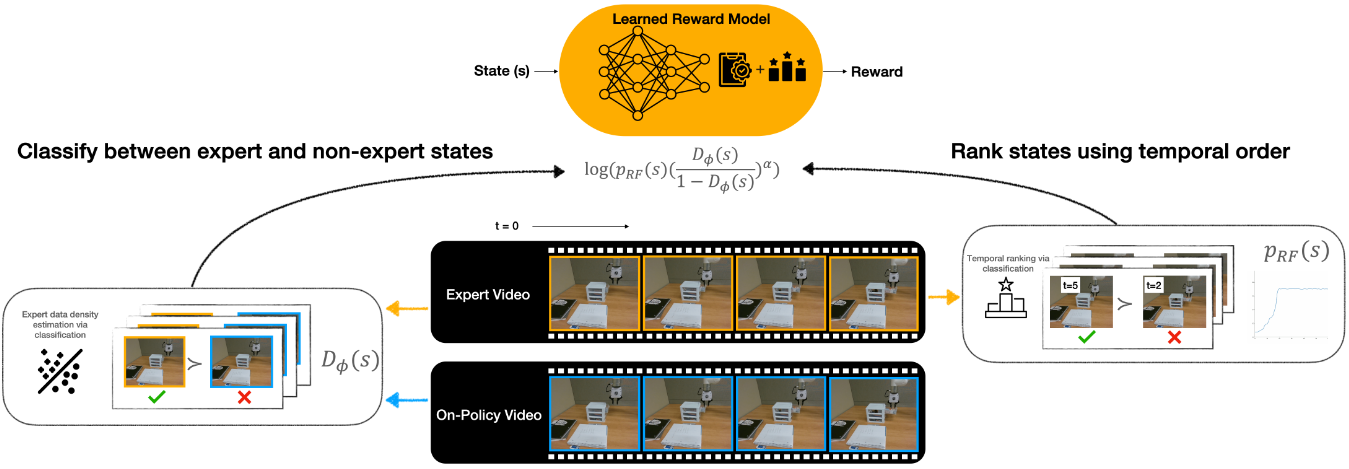 ## 互信息 ### Robot Data Curation
with Mutual Information Estimators (25, Google/Stanford)
理论
核心思想:选择状态多样、动作一致的轨迹
将上述思想转化为互信息:
## 互信息 ### Robot Data Curation
with Mutual Information Estimators (25, Google/Stanford)
理论
核心思想:选择状态多样、动作一致的轨迹
将上述思想转化为互信息:
实现
由于无法直接计算互信息,文中使用基于KNN的估计方式: 1.
学习低维表征:考虑到高维KNN距离难以估计,文中首先使用VAE学习第i个状态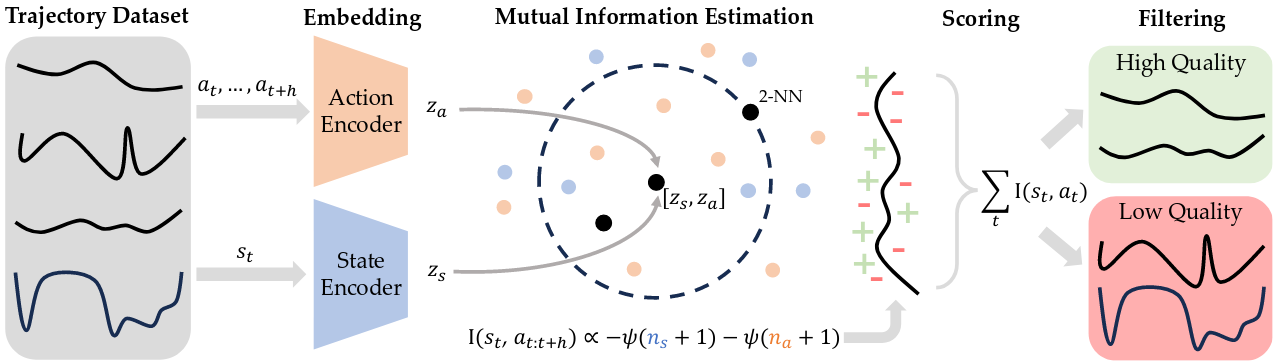
总结
| 指标 | 方法 | 物理意义 | 依赖数据 |
|---|---|---|---|
| 新颖性 | ThriftyDAgger | 预测动作的方差,反映模型对当前状态的不确定性 | 策略模型、状态 |
| 兼容性 | Multi-Human Compatible Metric | 结合状态常见性(新颖性低)与动作误差,去除常见但预测不准的状态 | 策略模型、状态、专家动作 |
| 强化学习 | VIP (Value-Implicit Pretraining) | 隐式学习当前帧与目标帧的特征距离,距离越小奖励越高 | 人类视频 |
| Rank2Reward | 排名分数(目标接近度) × 专家置信度的对数组合 | 专家视频、非专家视频 | |
| 互信息 | Robot Data Curation | 状态-动作互信息估计:状态多样性高 + 动作一致性高 → 分值高 | 状态、动作 |
缺点 1. 评分粒度太小:现有方法往往针对单个状态进行评分。。。 2. 泛化能力差:需要在当前任务上学习。。。 3. 依赖专业信息:需要提供专家动作标注或模型。。。