Latent Action调研
Object-Centric Latent Action Learning (2025.6)
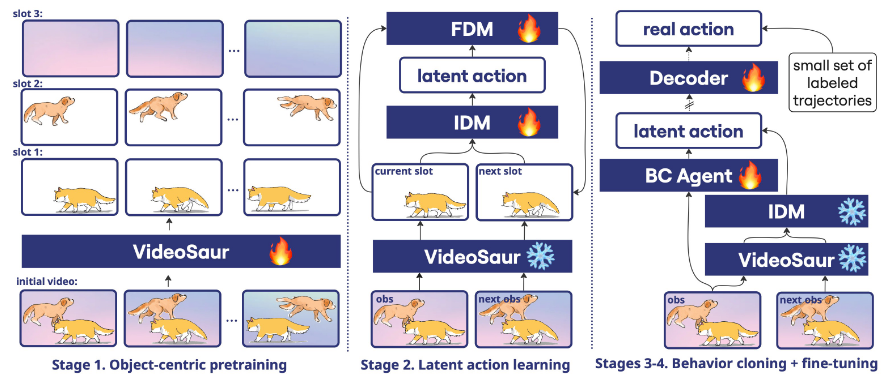
动机:视觉干扰物(如动态背景)在潜在动作学习中存在负面影响 方法:预训练视频模型将视频分解为可解释对象槽,通过线性回归选择前景对象槽学习latent
Physical Autoregressive Model for Robotic Manipulation without Action Pretraining (2025.9)
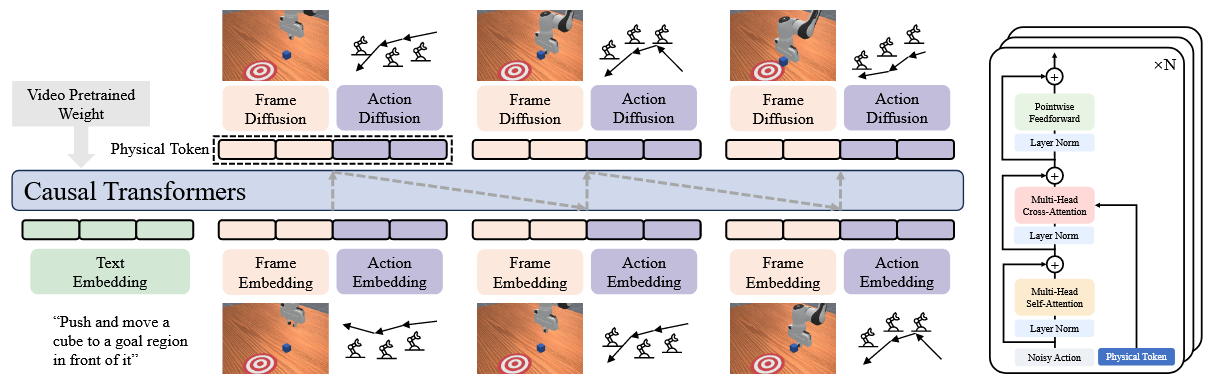 动机:VLA缺乏物理知识
方法:联合图像特征 +
动作特征作为latent(称为物理token),通过自回归预测未来的物理token
动机:VLA缺乏物理知识
方法:联合图像特征 +
动作特征作为latent(称为物理token),通过自回归预测未来的物理token
Spatial Forcing (2025.10)
ReconVLA (2025.8)
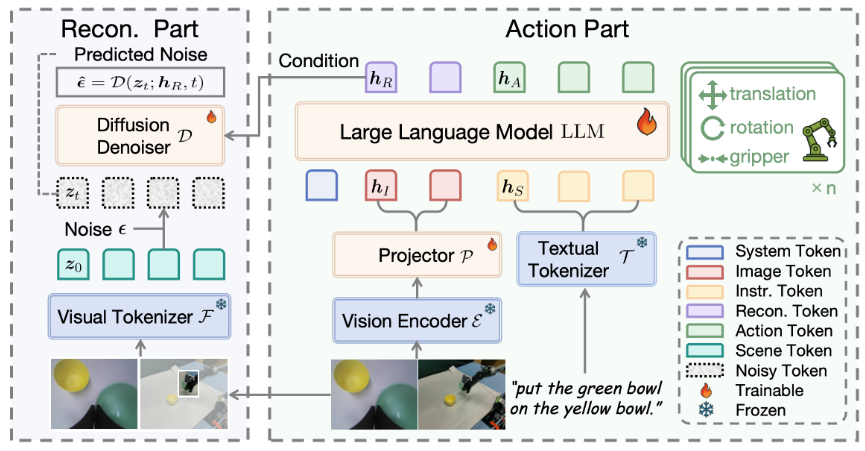 动机:VLA缺乏空间理解
方法:通过目标检测器提取物体feature作为latent的中间监督
动机:VLA缺乏空间理解
方法:通过目标检测器提取物体feature作为latent的中间监督
DreamVLA: A Vision-Language-Action Model Dreamed with Comprehensive World Knowledge (2025.8)
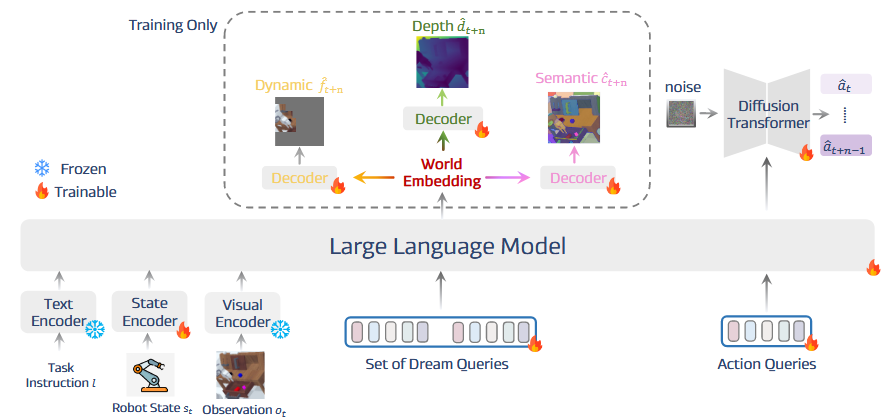 动机:VLA缺乏对世界的全面理解
方法:将运动、深度、语义信息作为latent的中间监督
动机:VLA缺乏对世界的全面理解
方法:将运动、深度、语义信息作为latent的中间监督
BridgeVLA: Input-Output Alignment for Efficient 3D Manipulation Learning with Vision-Language Models (2025.10)
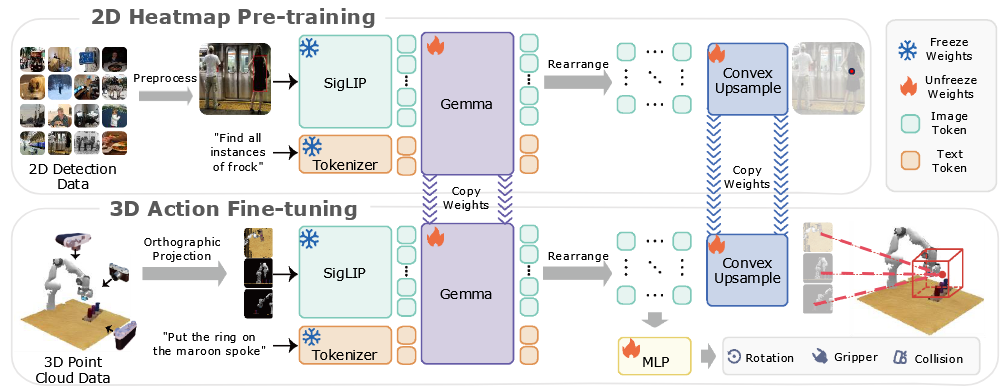 动机:VLA缺乏3D理解 方法:将latent
token重排列为voxel,预测多视角目标点位置,作为预测动作之前的额外目标
动机:VLA缺乏3D理解 方法:将latent
token重排列为voxel,预测多视角目标点位置,作为预测动作之前的额外目标
ContextVLA: Vision-Language-Action Model with Amortized Multi-Frame Context (2025.10)
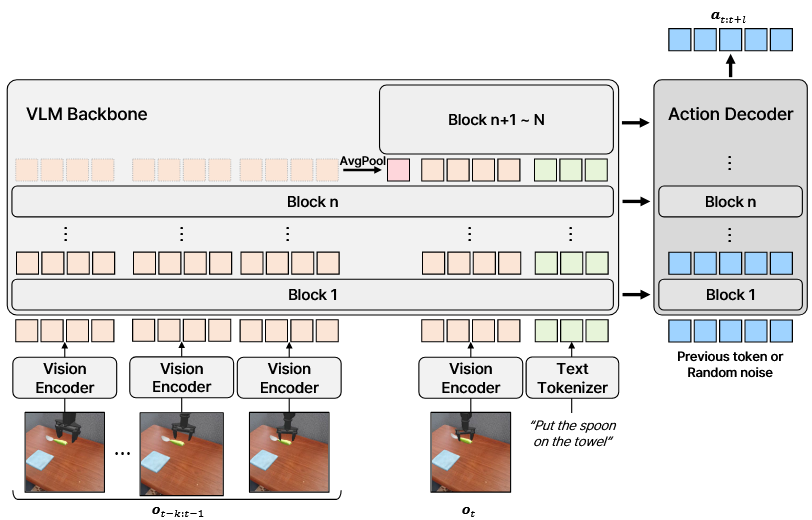
动机:VLA缺乏多帧历史观察序列理解,且计算成本高 方法:通过预训练VLM backbone提取时空特征,并采用平均池化进行标记融合,最终通过自回归或扩散模型生成动作
总结
- latent架构改进:通过slot等机制,提取去噪的前景信息
- 多模态融合:整合视觉、动作、3D信息,构建更丰富的latent空间
- 时序理解改进:改进历史信息、未来信息的学习机制
Latent Action调研