小目标检测的调研

小目标检测是目标检测的一大难点,由于像素信息小、样本不均衡、严重的遮挡和模糊等原因,小目标检测的性能一直很难被有效提升。近年来,顶会发布的针对小目标检测的论文并不多,大多数方法除了对小目标有效之外,其实对通用目标的性能提升也是有帮助的。
小目标的定义
小目标的定义有两种方式:
- 绝对尺度定义:根据目标的绝对像素大小进行定义。在MSCOCO中,将尺寸小于32x32的物体定义为小目标;在TinyPerson中,将像素值在20-32范围内的物体定义为小目标,将像素值在2-20范围内的物体定义为微小目标。
- 相对尺度定义:根据目标和图像的相对比例进行定义。例如目标的宽高小于图像宽高的1/10,目标的面积小于图像面积的3%等方法。
相关数据集
- Tiny Person:在视频中每隔50帧采集一次图像,共有1610个标记图像和759个未标记图像。

- City Persons:Cityscape的子集,只包含人的注释,有2975张训练图像、500张验证图像和1575张测试图像,提供了可视区域和全身的标注。

- iSAID:航空遥感图像的大型实例分割数据集,对DOTA数据集进行了像素级的标注和修正,包含2806张图像和655451个实例。
- Wider Face:人脸检测数据集,包含32203张人脸图像,393703个标注人脸,各类尺度变化,提供遮挡、姿态等标签。

小目标检测的问题
- 样本不清晰:小目标由于占有像素少,本身存在的模糊、遮挡等问题,其能够提供的特征信息十分有限,且容易受到环境的影响。
- 规模上的不平衡:在通用数据集中,小目标的样本数量往往比中大目标少很多,这导致中大目标提供的损失比小目标要大很多
- 正负样本上的不平衡:由于小目标的相对尺寸较小,其在特征图上占的比例也很低,这导致负样本提供的损失比正样本要大很多

定位困难
当前各种检测方法对于小目标没有中大目标友好。
例如,对于anchor-based检测器来说,中大目标相比小目标更容易被anchor框住,这意味着anchor-based检测器天生的就会采样更多的中大目标。
对于point-based检测器来说,各个特征点也更容易被中大目标的区域覆盖。
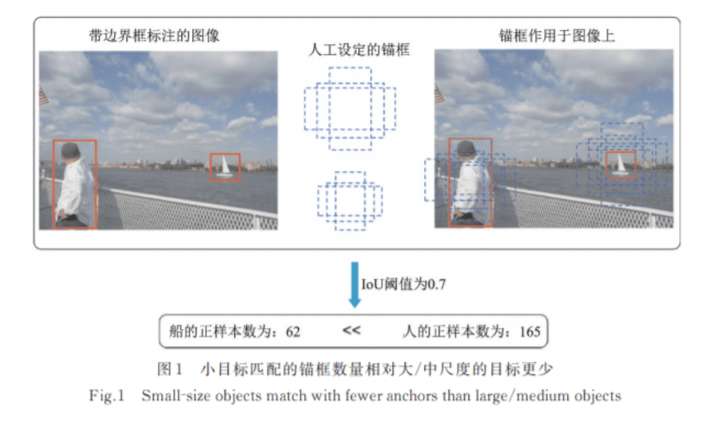
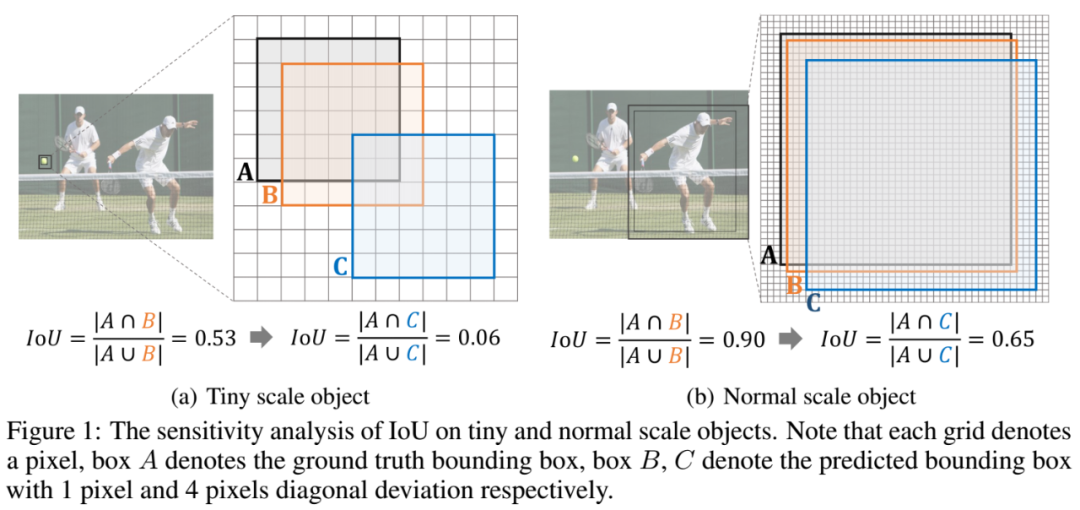
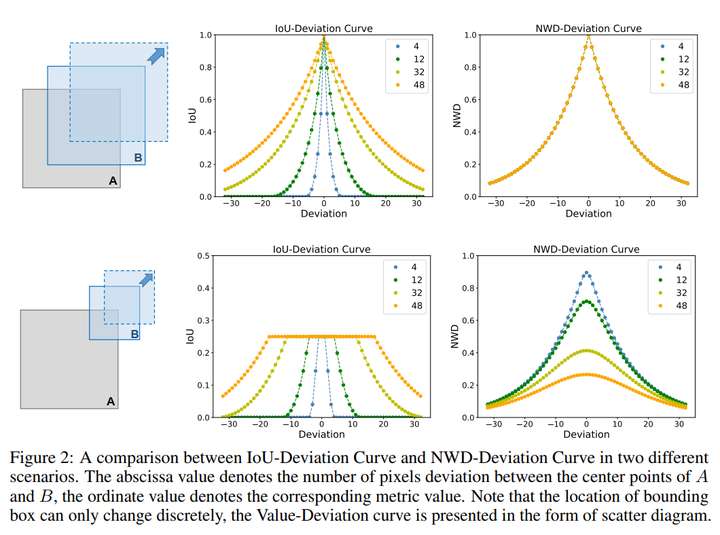
同时,基于IoU的目标框相似度的评估方法也对小目标天然不友好,IoU对小目标的位置变化非常敏感,对于相同像素范围的偏移,小目标的IoU变化比中大目标敏感得多。
现有方法
概述
我对近3年小目标上的检测方法进行了统计,选取论文共11篇。
从研究方向来看,多数论文还是在数据增强、多尺度学习、上下文学习等角度出发,一些对于小目标的特殊指标设计也不少见。
对多尺度学习的改进
目前几乎所有小目标检测的论文都采用backbone+FPN的基本结构,传统的FPN结构对中大型目标的检测表现出优越的性能,但是对小目标来说效果并不理想,具体体现在:
- 小目标对应的浅层特征层消耗了大量资源
- 深层特征向浅层特征的融合过程造成了小目标特征信息的干扰和丢失
许多论文从加强FPN特征融合的角度出发,做出了各种搭积木式的结构,但始终没有根本上的改变。

Gong(WACV 2021 Effective Fusion Factor in FPN for
Tiny Object
Detection)等人提出了一个融合因子来改进FPN的上采样策略。作者定义了融合因子,即深层向浅层融合的权重
传统的FPN的融合因子可看作1,然而作者发现,融合因子为1并不能给小目标带来最好的效果,这说明深层特征向浅层融合的过程中,如果权重过大,反而会干扰浅层原本的特征。

作者经过实验证明了融合因子影响的是目标的绝对尺度,并提出了融合因子的有效计算方法,可以达到近乎暴力搜索的效果。

Yang等人(CVPR 2022 QueryDet: Cascaded Sparse Query for Accelerating High-Resolution for Small Object Detection)则提出了一种巧妙的方式,在减少FPN计算量的同时提高性能。
作者认为FPN在上采样的计算中很大一部分是冗余的,同时,即便特征层无法精确检出小目标,也能粗略判断小目标的位置。
于是作者提出一种递归的方法:深层特征图粗略估计小目标的位置,指导浅层特征的计算。
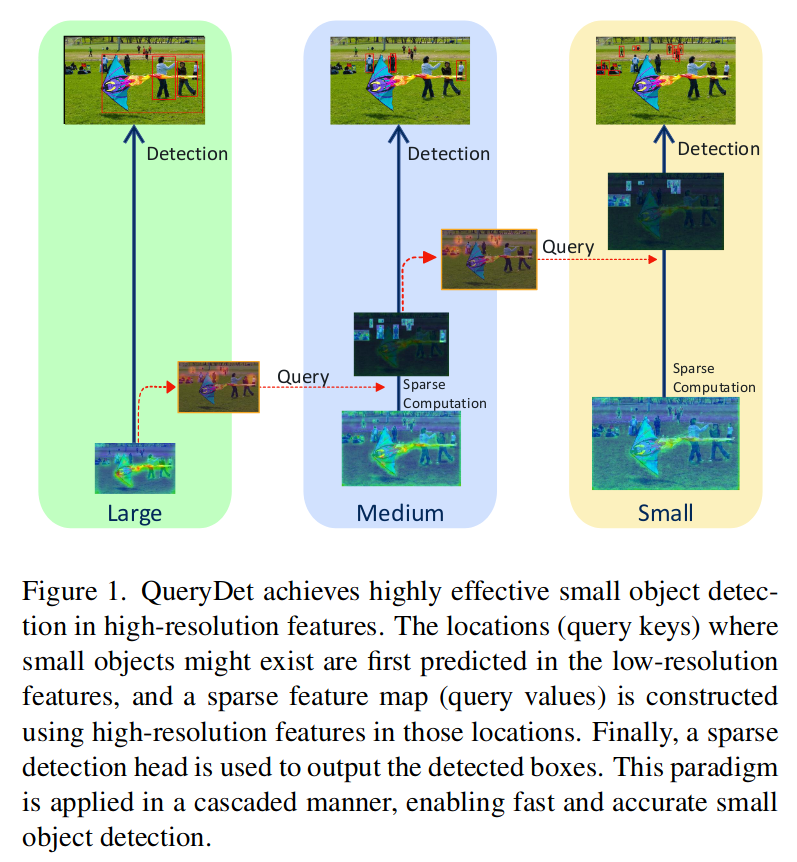
具体来说,每个head添加了一个query head,用于预测小目标所在的位置。深层head的预测结果将送入浅层,浅层只对深层query head预测的位置进行进一步预测。这样做不仅大大减小计算量(每个head只对query范围内的目标进行计算),还能大大缓解正负样本的不均衡问题,同时减少了冗余运算有利于提升效果。
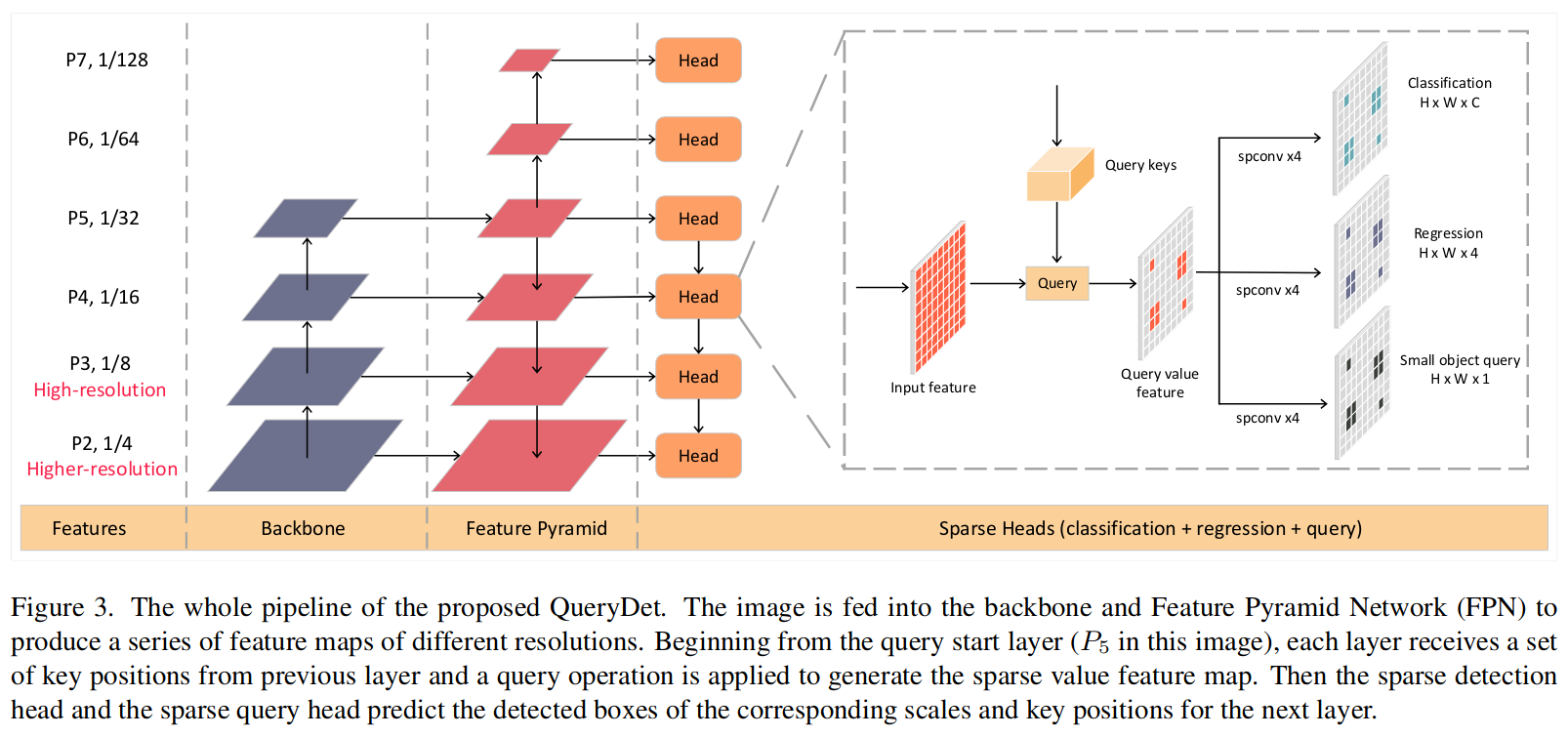
原本RetinaNet的P3层占据几乎一半的计算量,如果增加P2层还要占据超过一半的计算量,但如果采用QueryDet,计算量就几乎减少为之前的1/4。

总结:传统的FPN虽然在中大物体上表现出优越的性能,但在小目标上显得很乏力。无论是深层到浅层的特征融合设计,还是浅层面临的超大计算量(增加P2甚至会超过之前所有层的计算量)都在小目标检测上显现出瓶颈。
然而现有几乎所有小目标检测方法还是在FPN或类似结构上进行的,怎样改进FPN对小目标特征的提取效果和减少计算成本,或是提出一种新的结构,是小目标检测可以努力的方向。
数据增强
小目标本身就存在分布不均衡的问题,体现在小目标占比不均衡和占据的像素数量不均衡上。这类方法从数据的角度出发来平缓小目标的分布。
Chen等人( CVPR 2020 Stitcher: Feedback-driven Data Provider for Object Detection)提出了一种简单的方法:如果上一轮iter的小目标损失占比低,就将下一轮的图片缩小后拼接在一起,经过缩小,中大目标自然就变为小目标,这样就可以平衡小目标占比小的问题。
Yu等人(WACV 2020 Scale Match for Tiny Person Detection)对COCO等数据集进行采样,使得不同尺寸目标的数量分布更为接近,也提升了小目标的效果。
Zhang等人(WACV 2020 Robust Face Detection via Learning Small Faces on Hard Images)根据查准率对每张图像的难度进行评估,简单图像以更小的概率参加下一轮训练,这实际上就是增加了困难样本的训练比例,自然也增加了小目标参与训练的比例。
总结:数据增强的方法没有脱离对小目标和中大目标分布的均衡。有的方法通过减小中大目标的数量进行,有的方法通过平衡小目标和中大目标的训练进行,但最终实现的还是平衡小目标和中大目标参与训练的损失。
上下文学习
小目标不仅存在上述问题,其本身还存在模糊、遮挡占用像素空间小、提供信息量不足等问题,这些根本性的问题很难通过其它方法改进。一些研究都证明了引入上下文信息有利于提升小目标的检测性能,而对于大目标来说引入上下文可能还会带来性能下降。

Leng等人(Neurocomputing 2021 Realize your surroundings: Exploiting context information for small object detection)提出了用高质量检测框帮助低质量检测框的策略。
具体来说,作者给RPN额外添加了一个head用于预测每个候选框的质量,之后将候选框划分为高质量和低质量两部分。对于每个低质量框,与所有高质量两两组合成若干对,根据两框在外观上和几何上的相似度计算每对的权重,之后按权重重构每对的特征,再融合成新的特征。

Kim等人(ICCV 2021 Robust Small-scale Pedestrian Detection with Cued Recall via Memory Learning)则采用记忆网络,通过看到的小尺寸行人目标回忆起大尺寸行人目标的特征。

总结:近年来小目标的上下文学习更多在如何建立更好的显式上下文关系上进行研究,例如用高质量的预测框帮助低质量的预测框,或是用目标之间、区域之间的相似度等因素来建立关系,目前显式上下文关系的建立和推理还处在方法多样且不定的阶段,近年来图神经网络的发展也为建立数量不定、关系复杂的上下文关系提供了新策略。
特殊的指标设计
指标设计主要在于对IoU的设计和损失的设计。由于IoU对于小目标来说非常敏感,这导致预测框对小目标的定位非常困难。
Xu等人(CVPRW 2021 Dot Distance for Tiny Object
Detection in Aerial
Images)提出点距离来衡量目标框的相似度,具体来说,首先计算所有目标框的平均大小S,之后计算两目标框的中心点距离D,以
Wang等人(ISPRS 2022 Detecting tiny objects in aerial images: A normalized Wasserstein distance and a new benchmark)提出NWD,通过将目标框建模为二维高斯分布,之后计算指数归一化的两高斯分布的Wasserstein Distance代替IoU。这种方法对目标尺度不敏感,且可以保持连续性。
Liu等人(IMAVIS 2021 Feedback-driven loss function
for small object
detection)提出一种损失权重来平衡小目标的损失。对于每个目标,通过计算小目标损失占总损失的比例
总结:指标的设计主要是对IoU、loss等指标进行改进,改进的出发点有IoU的尺度敏感性和其它不合理、loss的不平衡(小目标和中大目标、正样本和负样本、多任务的不平衡等)、loss本身设计的不合理等问题。这也是一个目前仍不确定且长远的研究方向。
总结
目前对于小目标检测的研究往往不是单纯的针对如何提高小目标的效果,而是以下几个方向:
- 在小目标和中大目标之间作权衡,在保持中大目标性能的同时,提升通用目标检测中的小目标效果:尺寸不敏感的指标、平衡特征层的分配、平衡小目标和中大目标的数据分布等
- 提升高分辨率、密集图像的检测效果(城市密集人群、航拍图等):上下文学习、细粒度学习等
- 减少小目标所在特征层的冗余信息和计算量:一些特殊的设计
在20年的The 1st Tiny Object Detection Challenge挑战赛中,前三名队伍使用的结构还是backbone+FPN,少有的改进只是在FPN中增加了P2层,这说明即便是FPN,只要愿意牺牲更多的计算资源和时间,FPN仍然是提取小目标特征的有效手段。

近年来图像质量越来越清晰,使得即便切割成小图,图像也能保持高质量。最近提出的SAHI通过切片的方式辅助推理,使得YOLO这样不适合小目标检测的模型也能达到很好的效果,这说明只要愿意牺牲推理时间,切片这样简单方法的效果往往也能远超各种复杂的设计。

因此我认为当前小目标检测的研究不应拘泥于如何通过复杂设计提升图像中微小目标的质量,一些在数据层面作平衡的方法也已经比较成熟,在密集图像中利用关系进行推理,优化小目标特征层的信息特征表示、占用资源和计算量,以及不需要额外资源的适用于小目标的新指标仍然是可行的方向。
相关论文和简单的概括
- CVPR 2022 QueryDet: Cascaded Sparse Query for Accelerating High-Resolution for Small Object Detection 关键词:多尺度学习
利用CSQ机制提升小目标检测性能的同时节省计算量。具体来说,每一层添加一个head,用于输出小目标所在的位置heatmap,之后将每层的heatmap输入更浅的一层,而浅层只计算heatmap指定位置的类别、回归等信息。
- ISPRS 2022 Detecting tiny objects in aerial images: A normalized Wasserstein distance and a new benchmark 关键词:指标设计
提出了一种代替IoU的度量标准,将目标框建模为二维高斯分布,之后用Normalized Wasserstein Distance度量高斯分布之间的相似性。
- ICCV 2021 Robust Small-scale Pedestrian Detection with Cued Recall via Memory Learning 关键词:记忆学习、上下文学习
利用LPR记忆网络提升小尺寸行人的检测性能,利用小尺寸行人记忆得到大尺寸行人的信息。具体来说,对于backbone+RPN输出的若干目标框,根据尺寸区分出小尺寸和大尺寸的行人。对于小尺寸的行人,将其特征与LPR中的每个key计算余弦相似度,之后作softmax后作为权重,与LPR中的每个value加权求和作为强化后的特征。
为了保证value记住大尺寸行人的信息,需要将大尺寸行人用于LPR的训练。具体来说,将所有大尺寸行人的目标框切割并resize成一个大尺寸行人数据集,每个随机抽取若干图片,之后使用与主干网络相同的backbone提取特征。对于每个特征,与LPR中的每个value计算余弦相似度,并作softmax作为权重后与LPR中的每个value加权求和作为强化后的特征,计算强化前后的特征的差异作为损失。
- CVPRW 2021 Dot Distance for Tiny Object Detection in Aerial Images 关键词:指标设计
提出用点距离代替IoU,具体来说,计算数据集中所有目标的平均大小S,计算两目标框中心点的距离D,通过指数归一化得
- Neurocomputing 2021 Realize your surroundings: Exploiting context information for small object detection 关键词:上下文学习
利用目标间的上下文关系加强监测。在RPN中添加一个分支用于预测框的质量(事实上质量通过预测框和真实框的回归值经过线性变化后得到),之后根据每个框的质量和预测分数得到最终分数,将目标框划分为可信的和模糊的两大类。
设计了一个上下文推理模块用于增强候选框的质量:对于每个模糊框,与每个可信框组成若干个对,每个对根据两者的特征信息和最终分数经线性变换得到外观权重;根据两者的特征信息和回归信息经线性变换得到几何权重,相乘得到总的权重后作归一化处理,之后根据将每个可信框的特征乘以权重后拼接,最后根据原来的特征和拼接后的特征作变换得到最终特征,将特征放回特征图中以更新特征图。
设计了一个上下文特征增强模块用于增强最终的预测效果:对于每个候选框,与其几何特征拼接后融合,之后两两组合成若干组,经过线性层输出每组的类别和回归值。
- WACV 2021 Effective Fusion Factor in FPN for Tiny Object Detection 关键词:多尺度学习
FPN的融合可能对小目标检测带来两面的影响,作者提出融合因子,即深层特征向浅层融合的权重
- IMAVIS 2021 Feedback-driven loss function for small object detection 关键词:指标设计
小目标和大目标提供的损失是不平衡的,作者以YOLO为例,作者发现大目标提供的loss几乎是小目标的5倍,作者提出了feedback-driven
loss来解决问题:计算小目标损失占总损失的比例
计算损失权重。当小目标损失占比例很小时,该权重对小目标的增益就会越大,在训练过程中随着小目标权重增大,增益又会逐渐减小最终平衡,从而达到平衡小目标损失和其它损失的目的。
- CVPR 2020 Improving Multi-scale Feature Learning for Object Detection 关键词:多尺度学习
作者针对传统FPN的3个问题进行改进提出AugFPN:
不同层之间存在语义差距:在训练时对每层feature map进行分类和回归的监督训练,缩减语义差距。
最高层特征没有融合,且由于1x1conv损失信息:提出自适应空间混淆,将降维前的特征downsample成3份不同尺寸的特征图,降维之后upsample成尺寸和维度相同3个feature map,经过拼接和卷积生成每个feature map的空间注意力,之后加权求和
FPN每次只取一层的特征,如果目标特征位于两层之间就无法很好的提取特征:提出自适应通道混淆,将每层的ROI feature拼接,之后经过卷积生成每层的通道注意力,之后加权求和、
- CVPR 2020 Stitcher: Feedback-driven Data Provider for Object Detection 关键词:数据增强
作者发现多数训练过程中小目标损失几乎不占总损失的10%,作者提出了一种简单的方案:如果上一轮iter小目标的loss不足,就在下一轮中将batch内的4张图拼在一起,这样中大目标就被缩小成小目标,从而提供更多小目标的损失。
- WACV 2020 Scale Match for Tiny Person Detection 关键词:数据增强
作者制作了tinyperson数据集,并发现不同数据集的目标在尺寸上的分布差异很大。作者通过在尺度的分布上进行对齐制作了SM COCO和tiny citypersons数据集,取得了性能提升。
- WACV 2020 Robust Face Detection via Learning Small Faces on Hard Images 关键词:数据增强
通过动态为每张图像赋予difficulty score,以判断图像是否参与下一轮训练。初始赋予所有图像为hard image,之后对每张图像进行评估,若图像的WAPS>0.85就设为easy image,easy image以更小的概率参与下一轮训练。WAPS的计算方法为:对于图像中所有正样本,计算其被预测为前景的概率取最小值。
一些在FPN上搭积木的论文:
- Submitted to TGRS Attentional Feature Refinement and Alignment Network for Aircraft Detection in SAR Imagery
- arXiv 2021 Learning Calibrated-Guidance for Object Detection in Aerial Images
- arXiv 2020 MultiResolution Attention Extractor for Small Object Detection
- arXiv 2020 Extended Feature Pyramid Network for Small Object Detection
- arXiv 2020 MatrixNets: A New Scale and Aspect Ratio Aware Architecture for Object Detection